
Chapter 2: Grab the Dialogue#
Did you try running other text files through the script we developed together in the last chapter? If you haven’t, please try. Curiosity and experimentation are attitudes to nurture for they will make you a better problem solver.
Trying this will also solidify in your mind the difference between: (1) solving a particular instance of a problem; and (2) the construction of a script that solves many similar problems. Recall that the last chapter started with the goal of reading a particular book, but partway through the design, we adopted a change (which made our script independent of the input book’s length) and then added a Python input statement (which asked the user for the book they wanted read). This created a general solution that could read any book of any length.
Tip
There is real art in writing a script that solves a general problem. Throughout this book, we will write scripts that solve more than a single instance of a problem, and this will give you a good feel for the kinds of generality you can add to your scripts. On the other hand, you should not attempt to extend a script with every new “feature” you can imagine. Computer programs, as you have undoubtedly experienced in your life, can become large, buggy, and hard to use as they grow more “featuresome.” Do what seems reasonable, and think critically about every feature you include.
Writing scripts that are useful in a range of situations is what computer scientists strive to do. Under this approach, the solution to our problem is not just the output of our script, but also the script itself. You run the script, feed it the input appropriate for your current instance of the problem, and voilà, the computer follows the script and computes the desired answer.
What is the current task? In this chapter, we’ll again begin with a script that solves a simple instance of a problem and then expand it to solve a general problem. But there will be a new twist. Instead of having a loop perform a single task (e.g., reading and printing each line in an input file as we did in the last chapter), you’ll learn how to write a loop body that switches between tasks as it executes. We’ll use if-statements to control which statements in a loop’s body we want executed on each iteration; more importantly, we’ll create and update some program state that helps the script succinctly keep track of its current task.
Terminology
In general, program state is the set of all values known at a particular instant in a script’s execution. As an example of one piece of program state, consider the value of the_line after the first iteration of the while-loop from Chapter 1’s seuss.py script. This piece of state changes on each loop iteration.
To solve this chapter’s problem, our script will not only maintain the state directly involved in producing its output, but we’ll also have it create and manipulate additional information that the script uses to determine what it should be doing at each instant in its execution. You can think of this like a reminder note. As a busy person who frequently forgets why I walked into a room, I should more frequently make such notes!
Learning Outcomes
In this chapter, you will experience all eight steps in our problem-solving process. By the end of the chapter, you will be able to do the following:
Describe the importance of recognizing similarities and differences between problems when considering which past scripts might help you start writing a new script [design].
Use finite state machine (FSM) diagrams as a widely useful method for identifying and ordering the tasks that your script must perform while processing its input [design and CS concepts].
Convert FSM diagrams into pseudocode [design].
Think about strings as a sequence (i.e., an ordered collection of characters), understand the power of this sequence abstraction, and use several common operations on sequences [CS concepts and programming skills].
Perform string concatenation and understand operator overloading [CS concepts and programming skills].
Write for-loops that iterate over the items in a sequence [programming skills].
Become comfortable with all variations of if-statements [programming skills].
Develop test inputs, and recognize and employ a common design pattern for error handling [programming skills].
Explain off-by-one errors and recognize where this type of error often occurs [CS concepts and programming skills].
Structure your script development so that you interleave testing and coding. This way you can surface hidden assumptions and never go too long without an understanding of what works and doesn’t [design and programming skills].
Interpret the two ways of performing function composition in Python [programming skills].
A new problem. While Chapter 1 and some of its active-learning exercises (ALEs) had us decorate a story around its edges, our new problem-to-be-solved asks that we make the textual output of our script look quite different from its input. In particular, we’ll turn CatInTheHat.txt into a theatrical script that acouple of actors—playing the narrator, the Cat, the Fish, Things One and Two, and the Mother— could perform.[1]
What would be the problem specification? It could be something as seemingly simple: find the dialogue in the story and print it after the name of the character who says it.
Splitting the problem into small pieces. One of the keys to successfully writing a computational script is to break a large problem into small pieces (i.e., problem decomposition) and then write code to solve each of those pieces. Later, you can pull the pieces together to create the script that meets the entire specification.
What are the primary pieces in our problem specification? Well, we must:
find a story’s dialogue;
identify which character says which lines; and
ideally transform some of the story into stage directions around this dialogue.
Of these three things, let’s focus on finding the dialogue. Since each line of dialogue is enclosed in easily identifiable double quotes, we can precisely specify what we need to do. As incomplete solutions for the other two problem pieces, we will label the extracted dialogue with “ACTOR:” and skip adding any stage directions.[2]
With these decisions, Figure 5 shows how our script should print the first two pieces of dialogue from CatInTheHat.txt.
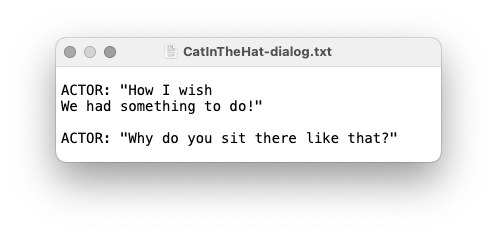
Fig. 5 The start of our script’s output given CatInTheHat.txt as its input.#
Reuse. We just practiced the first four steps of our problem-solving process: specify-imagine-decompose-decide. Step 5 asks if we can jump-start the writing of our script by reusing anything from a previously written script. To do this well, we have to think about the similarities and differences between our previous problems and this current problem.
Let’s begin with a slightly more robust version[3] of our final seuss.py script from Chapter 1:
1### chap02/read32.py
2my_book = input('What book would you like to read? ')
3
4with open('txts/' + my_book) as my_open_book:
5 while True:
6 the_line = my_open_book.readline()
7 print(the_line, end='')
8
9 # Check for EOF
10 if the_line == '':
11 break
12
13print("The End.")
This code queries the user for a book, opens the book, names the open-file object my_open_book, loops reading and printing each line from this object, closes the open file when the interpreter leaves the statements indented under the with-as-statement, and finally prints “The End.” Will we need to do similar work in our current problem? Yes. If we are going to find each piece of dialogue in a story, we’ll need to read each line in it. Let’s then keep this script’s first six lines. Of course, we will also need to know when we’ve reached the end of the story and when to close the open file, which the if-statement and with-as-statement do for us. Overall, we just need to adjust the input prompt and then delete the printing of the_line, since our new problem’s output is different. After doing all this, we’re left with the following:
1### chap02/script1.py
2my_book = input('What book would you like as a script? ')
3
4with open('txts/' + my_book) as my_open_book:
5 while True:
6 the_line = my_open_book.readline()
7
8 # Check for EOF
9 if the_line == '':
10 break
11
12 # new pseudocode goes here
13
14print("The End.")
Switching between goals. I put a comment where we’ll place our new pseudocode—at the bottom of the while-loop body—because we need to do something with the_line before we loop back. One way to figure out what we want this pseudocode to do is to think about what our script should be doing when it first starts reading the story. In other words, what is our script’s initial goal?
As the script begins, our initial goal is to find the start of the first piece of dialogue. Once found, our script switches to a new goal: scan to the dialogue’s end and print out what was scanned.
What happens then? We begin again searching to find the start of the next piece of dialogue, and the pattern repeats until the story ends.
Finite State Machines. What we just described is formally called a finite state machine (FSM). Each state in this FSM describes some work we need done. In switching states, our script looks for events. The script starts in some initial (or start) state and completes its work when it enters one of possibly several final (or end) states.
Figure 6 is a diagram of a FSM that solves our problem, where the states are represented as labeled circles (also called nodes) and transitions between states as directed arrows. Each arrow is labeled with the event that causes the transition. The initial state is identified by the special transition labeled Start.
Fig. 6 A complete FSM diagram for finding dialogue.#
Let’s take a moment and make sure we understand this diagram because it will be the template we use to write our script. The script needs to find each line of dialogue in our input file, and we know that dialogue is surrounded by double quotes. As indicated by the start arrow, our script begins in a state S0, which specifies that it should be searching the line it read for a double-quote character. If the line doesn’t contain a double-quote character, it should just move to the next line in the story. When the script finds a double-quote character, it has found the start of a line of dialogue, and this event causes a transition to the state labeled S1.
State S1 has our script do a different task: it collects the characters after the double quote, which it will later print as a piece of dialogue. The script continues to read lines and collect characters until it finds the next double-quote character in the story. This character indicates the end of the current piece of dialogue, and this event causes another state transition.
The transition out of state S1 takes us back to S0, since the script’s task is to again search for the start of a piece of dialogue. Our script will keep ping-ponging back and forth between these two states, collecting and printing dialogue, until what happens? Is there any other event to which our script should react?
Yes! Our input story eventually ends (i.e., our script hits the EOF). Figure 6 shows that we expect this event to happen while the script is in state S0. Why? What assumption are we making about the input story when this event is a transition from S0 to the FSM’s designated final state, which is labeled DONE?
While you think about this, I’ll tell you that the FSM in Figure 6 is what is formally called a deterministic finite state machine. Deterministic means that there is at most a single transition out of a state for each possible event. State S1 has two transitions out, but they are labeled with different events. There are also nondeterministic FSMs that allow a single event to label multiple transitions out of a state. You’ll encounter them if you continue to study computer science.[4]
Error handling in FSMs. Hopefully by now you have realized that the FSM in Figure 6 assumes that the input story is well-formed, meaning that every piece of dialogue in it starts and ends with a double-quote character.[5] The FSM doesn’t have a transition from S1 on EOF because we don’t expect our story to end while we are in the middle of a line of dialogue.
But what if our script is given an input story that isn’t well-formed? We might want our script to react in some predictable manner. We could think about solving this particular issue in the context of our particular FSM, but we could also try for a moment to think about any unexpected condition in any FSM.
The key is to realize that we can summarize the set of directed arrows in our FSM with a function (technically called a transition function) that maps states and input events to states (i.e., given the current state and an input event, this function returns the next state). For example, a transition function f for our FSM would return S1 when called with f(S0,'"').
Using this formulation, an unexpected condition corresponds to a state-event pair for which the transition function is not defined—f(S1,EOF) in our example. If we want a FSM to react predictably to such a pair, we need to define the transition function’s behavior. A straightforward solution is to create a new state, which signifies that an unexpected condition (or an error) has occurred, and make it the output of the transition function on that input pair.
We have only dipped our toes into the deep topic of FSMs. You will find that they are a great representation for modeling lots of mechanical, biological, and linguistic systems. But enough about the representation. Let’s use the diagram we’ve drawn to help us think about the code we want to write.
Encoding the state information. When implementing the FSM in Figure 6, the first thing to note is that it contains only three states, where the third state (DONE) represents the termination of our script. This means that our script has only to keep track of which of the first two states (S0 and S1) it is in at any point in time, which we can do with a single Boolean variable.
Let’s call this variable looking_for_open_quote and define its behavior so that it is True when the script is in state S0 and False when the script is in S1. Then, with the frame from script1.py, we can write Python code to initialize looking_for_open_quote (corresponding to the FSM’s start state) and use that variable to separate the work in state S0 from that in S1:[6]
1### chap02/script2.py
2my_book = input('What book would you like as a script? ')
3
4with open('txts/' + my_book) as my_open_book:
5 # Set our FSM to the start state
6 looking_for_open_quote = True
7
8 while True:
9 the_line = my_open_book.readline()
10
11 # Check for EOF
12 if the_line == '':
13 break
14
15 # new pseudocode goes here
16 if looking_for_open_quote: # in S0
17 # Do some work
18 else: # in S1
19 # Do other work
20
21print("The End.")
Notice that the script pulls the processing that every state does (i.e., reading a line of characters from the input file) out of each state’s work. We will talk more, in the next chapter, about the benefits of collecting commonly executed code together in one place.
This or that. You’ll also notice, in script2.py, a new syntactic structure for the Python if-statement. Compare it with the if-statement immediately above it, which is used to check for our infinite while-loop’s exit condition. In checking for EOF, the if-statement protects the break-statement: we either hit this condition or continue with the loop’s work. In checking for something exceptional like this, the if-block and its controlling condition provide all the structure we need.
In testing the value of looking_for_open_quote, we need to decide which of two pieces of work we want to do, and we must do the work in one of these two states before moving on. While we could write an if-statement to check one of the conditions and then follow it with another if-statement checking the other condition, Python provides a form of the if-statement that eliminates this unnecessary second check. In this form, the second if-statement becomes a simple else.
Tip
Why is an if-else-block better than two if-statements in this situation? Because the condition we’re checking is either true or false. When it’s not one, it must be the other. If you write two if-statements, you’ll have to correctly write a condition and its complement. The if-else construct removes this unnecessary work (and the potential error in logic or typing waiting to happen).
Work on a state. Let’s work next on the logic in state S0. What do we need to do in it? For one thing, it can ignore any line that does not contain a double-quote character. But if the line contains a double-quote character, we know that the line is, at least, the beginning piece of a line of dialogue. I say “at least” because the dialogue that starts on this line may end on this line or extend to one or more following lines.
I want to pause here and highlight the fact that we are using the word “line” in two different contexts that we must keep straight. A line from the file, which is completely contained in the object called the_line, and a line of dialogue from the story, which can start anywhere in a file line and continue to an arbitrary point in that or a later file line. For example, the first line of dialogue in The Cat in the Hat starts in the middle of the eighth file line and continues to the end of the ninth file line.
### Lines 8 and 9 of CatInTheHat.txt
8 And I said, "How I wish
9 We had something to do!"
Let’s start to implement these ideas by focusing first on the transition between states while in state S0.[7]
15 ### Part of chap02/script3.py
16 if looking_for_open_quote: # in S0
17 # Do some work
18
19 # Part of which is transitioning between states
20 # if found opening double quote
21 # move to s1
22 # else
23 # stay in s0
Notice that line 20 uses an if-statement to check for the event that causes the transition from S0 to S1. This event is the presence of a double-quote character in the_line. So, how do we check for a double-quote character in the string object named the_line?
Strings as a sequence of characters. To this point, I’ve been relying on your intuition for what constitutes a string in Python. We created them by defining string literals. We read file lines as strings and compared them against string literals (e.g., to test for EOF). And we printed them out to the console.[8] Probably none of this work forced you to think about how we were representing strings in the computer; we simply operated on them as big blobs. However, to ask whether a string contains a particular character, we must know if Python allows us access to the components of a string object.
Short answer: it does. A string in Python is a sequence of characters. I emphasized sequence in this definition because sequence is a very useful abstraction for lots of different objects that we’ll manipulate in our scripts. The abstraction you should have in your mind for a sequence is an ordered collection of items.
It doesn’t matter if the items in a sequence are of the same type or kind, although in the case of a string, each item in the ordered collection is of the same kind (i.e., a character). We will soon play with the list data type in Python, which allows you to create a sequence containing different kinds of things. For example, the objects on my office bookshelf when viewed from left to right could be represented as a Python list containing a stuffed animal, a picture of my kids, this course’s textbook, an old compact disc, and then some other books.
Membership test. What makes a sequence a useful abstraction are the commonly used operations that query or manipulate Python sequences without needing to know anything more specific about the actual sequence. For example, we can ask about the length of a sequence, and it doesn’t matter if we’re asking about the number of characters in a string or items in a list. All that matters is that the object whose length we’re interested in acts like a sequence so that Python can answer with a count of the number of items in the collection.
Another commonly used operation on a sequence is a membership test, which asks whether a specified item is a member of the specified sequence. Note that a membership test is exactly what we need to determine whether the string named the_line contains a double-quote character. The Python operator for a membership test is in, and you start your question with the item you want to know if it is in the sequence. With this, let’s turn our pseudocode if-statement into Python code!
15 ### Part of chap02/script4.py
16 if looking_for_open_quote: # in S0
17 # Do some work
18
19 # Part of which is transitioning between states
20 if '"' in the_line:
21 # move to s1
22 else:
23 # stay in s0
If you wanted to know that there was no double quote in the_line, you’d write the expression: '"' not in the_line. Both in and not in are binary infix operators, and both return True or False.
Coding a transition. To transition from state S0 to state S1 (i.e., pseudocode line 21), we simply need to appropriately set our state variable,[9] which in this case means setting looking_for_open_quote to False. Staying in S0 is even easier: looking_for_open_quote stays True, and this means we can delete the entire else clause since there’s no work to be done (i.e., it is already True in this code block!).
15 ### Part of chap02/script5.py
16 if looking_for_open_quote: # in S0
17 # Do some work
18
19 # Part of which is transitioning between states
20 if '"' in the_line:
21 looking_for_open_quote = False
Indexing and slicing. I left the comment “do some work” because transitioning on seeing a double quote is not all we need to do. To print each line of dialogue, we need to capture the characters we read from an opening double quote until its matching ending one. Python makes this work easy with indexing and slicing operations on sequences.

Fig. 7 How Python numbers each character in a string, or more generally in a sequence.#
To use these operations, you need to understand how Python numbers a sequence’s items. Figure 7 illustrates this numbering using a string corresponding to line 8 of the file CatInTheHat.txt. Notice that Python—like many program languages—starts numbering the items at 0. If the string in Figure 7 was named the_line, then writing the_line[0] would return the string 'A', the first character in our example string. Asking for the_line[1] returns the second character. This use of square brackets is called indexing.
1the_line = 'And I said, "How I wish\n'
2print(the_line[0])
3print(the_line[1])
You Try It
Go ahead and use the interactive Python interpreter to experiment with statements in this section’s code blocks. The more you play the better you’ll understand how indexing works.
As I mentioned earlier, you can ask for the length of a sequence object. You do it with the Python built-in function len. For example, len(the_line) returns 24. Notice that it counts letters, spaces, punctuation, and the special newline character at the end of this string. These are all items in the sequence named the_line.
1len(the_line)
While counting from the front of a string is often what you need, sometimes it’s more natural to your problem to count backwards from the end of the string. This is possible in Python by using negative indices. The last character in our the_line example is accessed by writing the_line[-1], and the initial capital 'A' is the_line[-24] or the_line[-len(the_line)]. You will get an IndexError if the index you use for a given string s is less than -len(s) or greater than or equal to len(s).
1print(the_line[-24]) # prints the first character
2print(the_line[-len(the_line)]) # also prints the first character
3the_line[len(the_line)] # index out of bounds!
Indexing is helpful, but what our problem needs is the ability to grab a subsequence of characters from the full sequence. To do this, we can use Python’s slicing facility, which adds a colon and second index into the square brackets. For example, the_line[6:10] returns the string 'said'.
1print(the_line[6:10])
Notice that the first index in this expression (i.e., the one before the colon) is the index of the first character of the slice we want, but the second index in this expression is one greater than the index of the last item in our slice. Defining the slicing operation in this manner allows us to write the_line[0:len(the_line)] to create a copy of the string object named the_line. Since programmers will often find themselves writing 0 as the first index and len(s) as the second index in a slice, where s is a name for some sequence object, Python will assume you mean 0 as the first index if you elide it and len(s) as the second index if you elide it. To copy a string s, therefore, you can simply type s[:].
I tell you all this because we want the slice the_line[12:] as the start of our dialogue line.
1the_line = 'And I said, "How I wish\n'
2print(the_line[12:])
But how do we know that the double quote sits at index 12? All that the in operator told us was that a double-quote character existed in the_line.
For-loops. Programmers ask this type of question often enough that the developers of Python made it easy to answer. But I’m going to divert us for a moment to talk about how, for example, a beginning programmer would solve this problem without using this Python aid. This aside introduces to you the other major looping construct in Python (and many other languages): the for-loop. More importantly, it will help you to understand what takes place behind the scenes in the Python aid that we’ll eventually use.
The following code block fills in more of the work we need done in state S0. It uses a for-loop to find the location of the first double-quote character in the_line and then begins capturing the dialogue.[10]
15 ### Part of chap02/script6.py
16 if looking_for_open_quote: # in S0
17 # Do some work
18
19 # Part of which is capturing dialogue
20 for i in range(len(the_line)):
21 if the_line[i] == '"':
22 dialog = the_line[i:]
23 break
24
25 # Part of which is transitioning between states
26 if '"' in the_line:
27 looking_for_open_quote = False
The for-statement on line 20 iterates over the items in a sequence. The in keyword here plays a similar membership role as we saw earlier, but this time, we are asking i to name each item in the specified sequence in order, and for each of those values, execute an iteration of the indented block of statements (i.e., the body of the for-loop).
To see this for-loop in action, we need to know what the sequence is in this particular case. We already know what value is produced by len(the_line), and we pass the integer value computed by it to another Python built-in function called range. This built-in is quite interesting, but for now, we simply need to think of it as computing a sequence object containing the integers from 0 to one less than the integer value passed to range.
Let’s now look at the body of the for-loop in the code block above. It asks whether the character at index i in the_line is a double quote. When it is, the body of the if-statement names the slice of the_line from i to the end of the_line with the variable dialog. We end the if-statement body with a break because we don’t need the for-loop to continue checking the rest of the_line once we’ve found a double quote. (Actually, there are other cases that we need to handle, but not for our example from line 8 of CatInTheHat.txt.)
Our original if-statement that checked for a double-quote character in the_line is now performing redundant work when the for-loop finds a double quote. We can rewrite the work in state S0 to integrate the transition work into the for-loop.
15 ### Part of chap02/script7.py
16 if looking_for_open_quote: # in S0
17 # Look for an opening double quote
18 for i in range(len(the_line)):
19 if the_line[i] == '"':
20 # Capture dialogue and transition to S1
21 dialog = the_line[i:]
22 looking_for_open_quote = False
23 break
Tip
If you find the logic hard to follow in the last code block, you’re not alone. While logically correct, the three things we had to do—(1) check for the presence of a double-quote character, (2) start capturing the dialogue if found, and (3) decide whether to stay in one state or transition to the other—are now all muddled together. Sometimes a solution that does a bit more work is better because it is easier to understand and faster to get correct. Unless you know that performance is an issue, don’t prematurely optimize for it.
String find. We don’t have to write a for-loop to find the index of the first occurrence of a double-quote character because the Python language includes a str.find method, which does much of the work for us. Notice that I don’t say “all of the work.” The method is a bit tricky in how it lets you know that it didn’t find the substring you sought. When this is what the method needs to communicate, the value it returns is -1, which is not an index value but an indication that there’s no index to return. In other words, given a string s and a substring c, s.find(c) returns an integer between 0 and len(s)-1 if c occurs within s and -1 if not.
15 ### Part of chap02/script8.py
16 if looking_for_open_quote: # in S0
17 i = the_line.find('"')
18 if i != -1: # Was the find successful?
19 # Found an open quote
20 dialog = the_line[i:]
21 looking_for_open_quote = False
Tip
Because the if-statement on line 18 isn’t self-documenting (i.e., it doesn’t look anything like the question we’re asking), I’ve added a comment to explain its purpose. The if-statement on line 16, in contrast, is better at self-documentation. The comment there simply reminds us which state corresponds to looking for an opening double quote. You don’t need to comment every line in your script if their purpose is clear, but you should definitely comment those that are confusing (e.g., line 18) and when you want to tie your design work to your code (e.g., line 16).
Design patterns for error handling. When you have been programming long enough, like any practiced skill, you’ll start to see repeated patterns. The special use of the value -1 is a common one for error handling. A command, function, or method carves out one or more values and distinguishes those values as error conditions. In our current example, find needs only the integers in the range 0 to len(s)-1 to fully accomplish its stated functionality. The person who wrote the implementation of find was free to pick any value outside this range of valid results as an error condition and might have picked several such values to indicate a number of different error conditions.
One of the things you’ll learn as your programming skill grows is that you should always check and handle the error conditions that might occur in the commands, functions, and methods you use. The only reason not to do this is because you have carefully reasoned out why the error condition cannot occur.[11]
Unfortunately, just because a design pattern is commonly used doesn’t mean it isn’t without headaches. This pattern requires us to add the statement if i != -1: to our script, which we are supposed to read as “if find returned a valid index into the_line then we found an opening double-quote character at index i.” Yeah, it doesn’t look much like that to me either (and hence our added comment).
While the structure of the logic is not the issue, many programmers also dislike this design pattern because it can break up a script’s flow with lots of checks for uncommon error conditions. When we are constantly distracted by infrequently true error checks, it can make it very hard to read the script to understand its primary function. We can solve this headache by using a different design pattern for error handling, which keeps exceptional events out of the main flow of your algorithm. We will talk about this other design pattern in a later problem-to-be-solved.
Never go too long without testing. We’ve made great progress on our script. Now we have a choice to make about how to proceed. On the one hand, we can continue to write code to handle all the cases that might occur in state S0 (e.g., a piece of dialogue that is completely contained within a file line). Our minds are focused on S0, and it may be enticing to continue until we’ve handled every case we can imagine. On the other hand, we could switch and start writing some code for state S1. In particular, we could write S1 code that complements the code we just finished in S0. The benefit of this approach is that it would allow us to see if we can get our script to run on some subset of the possible inputs.
Tip
When given the opportunity to test what you’ve written, take it. It’s a good practice to build your script in pieces that you can regularly test. I like the feeling of accomplishment when I get another small piece of my problem to work. Plus, it is often efficient from an overall time perspective if you don’t spend a lot of time coding a design that was doomed to failure based on one of your early design decisions. Regular testing will keep you from wasting a lot of time on doomed designs. The exercises and problem sets that come with this book are structured to encourage you to follow this approach.
So let’s move toward a script we can test. What do we need to write for state S1 that integrates with what we just finished writing for S0? When our script is in state S1, it is looking for the close quote matching the open quote seen in state S0. This sounds a lot like the work we just finished.
In both states, we use the find method on strings to determine whether the_line contains a double-quote character, and if it does, we either start capturing (state S0) or finish capturing (state S1) the dialog. We also include a FSM transition in each case, which involves setting looking_for_open_quote appropriately. Finally, we will need to print in state S1 the dialogue we captured, as the specification required us to do. Here’s that code for states S0 and S1.
15 ### Part of chap02/script8.py
16 if looking_for_open_quote: # in S0
17 i = the_line.find('"')
18 if i != -1: # Was the find successful?
19 # Found an open quote
20 dialog = the_line[i:]
21 looking_for_open_quote = False
22 # FIXME! Need to handle short dialogue.
23
24 else: # in S1
25 i = the_line.find('"')
26 if i != -1: # Was the find successful?
27 # Found a close quote
28 dialog += the_line[:i+1]
29 print("\nACTOR:", dialog)
30 looking_for_open_quote = True
31 else:
32 dialog += the_line
33 # FIXME! Is this all the work in state S1?
Concatenation, overloading, and shorthands. Let’s go through the code for state S1, which will highlight two important things: (1) a design difference between the two blocks; and (2) a common shorthand you’ll see in Python code.
First notice that the if-statement on line 26, unlike its sibling on line 18, does something for both the case of finding a double quote in the_line and not finding one. When the script finds a closing double quote, it adds the remaining dialogue to the variable dialog. By add, I mean concatenate. As you learned in ALE 1.3 from Chapter 1, the + operator concatenates when its operands are strings and adds when its operands are numbers. This is called overloading: the operation of the operator depends on the type of its operands.
The S1 code also adds all the characters in the_line when it doesn’t find a double-quote character. This is because everything in the current file line is part of the running dialogue.
But wait, these two concatenation operations don’t look quite like what we saw in the last chapter. What is the meaning of this += operator where we expect the concatenation we just discussed to occur? Well, += is just a shorthand for a concatenation that is really an append. In other words, the statement dialog += the_line is equivalent to the statement: dialog = dialog + the_line.
Off-by-one and other potential errors. Now look carefully at what we append to dialog when the script finds a double-quote character. Do you fully understand why the_line[:i+1] includes the ending double quote? If not, you may wish to read the documentation about the string method find and review how the indices in slicing work. If you left off the +1 in the_line[:i+1], this would be an example of what’s called an off-by-one error. They are quite common in programming, and you should train yourself to be alert to situations where they can occur.
As I did for S0, I added a comment at the end of the code for state S1 to remind us that we haven’t carefully considered all the cases that can occur when looking for dialogue. We have neither tested on a lot of different examples nor carefully thought through the cases we might encounter. But that’s OK for now, since we simply want to see if we can get the script to work for the cases we think we have covered.
Testing. Typically, you start testing with small inputs to see if your script operates as you expect. This is a great method for incrementally learning what works and clearly seeing what doesn’t. Being methodical may not be your style, but it makes testing and debugging less of a nightmare.
Here’s the full script we’ve developed to this point:
1### chap02/script8.py
2my_book = input('What book would you like as a script? ')
3
4with open('txts/' + my_book) as my_open_book:
5 # Set our FSM to the start state
6 looking_for_open_quote = True
7
8 while True:
9 the_line = my_open_book.readline()
10
11 # Check for EOF
12 if the_line == '':
13 break
14
15 # new pseudocode goes here
16 if looking_for_open_quote: # in S0
17 i = the_line.find('"')
18 if i != -1: # Was the find successful?
19 # Found an open quote
20 dialog = the_line[i:]
21 looking_for_open_quote = False
22 # FIXME! Need to handle short dialogue.
23
24 else: # in S1
25 i = the_line.find('"')
26 if i != -1: # Was the find successful?
27 # Found a close quote
28 dialog += the_line[:i+1]
29 print("\nACTOR:", dialog)
30 looking_for_open_quote = True
31 else:
32 dialog += the_line
33 # FIXME! Is this all the work in state S1?
34
35print("The End.")
Our first test input is Talkative1.txt, which contains two paragraphs from the Indian fairy tale titled The Talkative Tortoise. When you run script8.py and tell it to read Talkative1.txt, it should work as we expect: The single line of dialogue (across multiple file lines) is printed. That’s not what will probably happen on most of your first test runs, but one can always hope!
Tip
When testing a script that repetitively does something, first test with an input that requires only one iteration of your repetitive action. This is what Talkative1.txt did; it caused our script to visit state S0, then state S1, and then exit. Once one iteration works, try an input that causes two iterations. Proceeding like this separates the testing of the work within an iteration from the work a script does to move from one iteration to the next.
Let’s now try our script on a test input file containing two lines of dialogue. Run script8.py on Talkative2.txt. Success again!
So far so good, but what about the case of a story with a line of dialogue fully contained on one line of the input file. The file HomeView3.txt contains this case, which is a paragraph from the first chapter of Five Little Peppers by Margaret Sidney (a pseudonym for Harriett Lothrop). Run script8.py on this input, and let’s see if we really need extra code to handle this case.
Hmmm, I guess we do. This test run failed to do what we expected; it prints a bunch of text that isn’t dialogue and ends at the start of the second quote in the input file.
Function composition. Once we have thought through the problem and outlined a sensible solution, implementing it is fairly straightforward. In script9.py, I’ve protected the transition to state S1 (within the S0 work) with an if-statement that makes sure that the rest of the file line (i.e., dialog[1:]) does not contain a double-quote character. If it does, we slice out the short line of dialogue, print it, and stay in state S0 looking for the next open quote (i.e., the body of the new else within the S0 work).
1### chap02/script9.py
2my_book = input('What book would you like as a script? ')
3
4with open('txts/' + my_book) as my_open_book:
5 # Set our FSM to the start state
6 looking_for_open_quote = True
7
8 while True:
9 the_line = my_open_book.readline()
10
11 # Check for EOF
12 if the_line == '':
13 break
14
15 # new pseudocode goes here
16 if looking_for_open_quote: # in S0
17 i = the_line.find('"')
18 if i != -1: # Was the find successful?
19 # Found an open quote
20 dialog = the_line[i:]
21 if '"' not in dialog[1:]:
22 looking_for_open_quote = False
23 else:
24 # Grab entire dialog from this line ...
25 short_dialog = dialog[1:].split('"')[0]
26 print("\nACTOR: " + '"' + short_dialog + '"')
27 # ... and stay in state S0
28
29 else: # in S1
30 i = the_line.find('"')
31 if i != -1: # Was the find successful?
32 # Found a close quote
33 dialog += the_line[:i+1]
34 print("\nACTOR:", dialog)
35 looking_for_open_quote = True
36 else:
37 dialog += the_line
38 # FIXME! Is this all the work in state S1?
39
40print("The End.")
The syntax on the righthand side of the = operator where we set short_dialog (line 25) is a bit intimidating, and let’s take a moment and make sure we understand exactly what it does. The key to understanding is to remember that the Python order of computations takes place left to right.
With that in mind, we can understand dialog[1:].split('"')[0] as saying: Take the object named dialog and treat it as a sequence. We want every item in this sequence except the first (i.e., excluding the 0th item), as specified by the slice dialog[1:]. Next, split this result into a list of subsequences using the double-quote character as the splitting point, as specified by .split('"'). The double-quote character is not included in the resulting subsequences, and the list returned by split is itself a sequence. We index into this list to grab the first item (i.e., at index 0), which turns out to be everything in the_line between the opening double quote and the ending double quote! This explains why the subsequent print concatenates the opening and closing double-quote characters back onto the short_dialog as we print it.
The righthand side of the short_dialog assignment statement is an example of function composition, and we will see it used often. In fact, we saw an earlier example in our for-loop code (i.e., range(len(the_line))). This example looks a lot like function composition in mathematics, where you evaluate the stuff in the innermost pair of parentheses first and then work your way out to the outermost parentheses. Overall, try not to let either of these different forms of function composition overwhelm or intimidate you. When you come across them, just take them a step at a time. In this next example,[12] you’ll eventually come to appreciate that
1dialog = '"At least I\'ll try."'
2short_dialog = dialog[1:].split('"')[0]
3short_dialog
is easier to read and comprehend than
1dialog = '"At least I\'ll try."'
2dialog_and_other_stuff = dialog[1:]
3list_of_dialog_and_other_stuff = dialog_and_other_stuff.split('"')
4short_dialog = list_of_dialog_and_other_stuff[0]
5short_dialog
Function composition removes the need to give names to the intermediate results, and without names, our attention is not drawn to this work, which is necessary for the computation but not important to the big picture. This point is important. For human readers, your script should be like a good story: It highlights the main action while hiding the details of exactly how the characters interact and get from place to place. But unlike a literary story, your script does contain these details, through the mechanism of function composition. The Python interpreter needs to know these details, since it does only what it is exactly told to do. Function composition keeps humans from being distracted by the details the interpreter needs to know.
Abstraction as information hiding. For another example of where we hid details to help with human understanding, recall how we replaced a for-loop and its associated code with an invocation of the find method on a string. Both computed a similar result, but we preferred the find string method over the for-loop implementation because it was both more concise and more expressive of what this step in our script was doing. In the next chapter, we will see how we can create our own compact representations—abstracting away the details—so that each line of our script more closely resembles each step in the pseudocode we are trying to implement.
There is no character. Before we go, I want to correct something you may have come to believe. While I have used the term “character” to describe single items in the sequence known as a Python string, there is no distinguished thing that is a character in Python. What we think of as a character is just a Python string of length 1. In other words, when I earlier wrote that the_line[0] returns 'A', I was careful to write the result as a Python string. Go ahead and see what type(the_line[0]) tells you about the type of the object returned from the string index method. We will talk more about types when we reach Act II.
>>> the_line = 'And said, "At least I\'ll try."'
>>> type(the_line[0])
<class 'str'>