
Chapter 11: Discover Driving Directions#
We began this act with a search problem that asked us to create a listing of all webpages that mention a particular keyword or phrase. Search was effectively a question of matching. Are there search problems that are more than just matching against a pattern? Google definitely thinks about search much more broadly. It searches over many different sources of digital information seeking answers to our questions.
In this chapter, we expand our definition of a search problem to include the many processes we use in our daily lives to find solutions to questions for which we have a well-described goal. We consider several different instances of this issue, but one of the most recognizable examples of goal-directed search is the finding of a path from one point on a map to another.[1] You have almost certainly used this type of software in driving across the country or walking in an unfamiliar city, and how such software works is this chapter’s problem-to-be-solved.
A new approach to programming. In addition to introducing a new problem-solving technique (i.e., goal-directed search), this chapter’s problem requires us to move beyond a procedural approach to programming. To this point, we decomposed each problem into functional components and then “wired” these components together in a sequence of steps that, when executed, produced a solution. This approach is not that much different from the recipes we follow when cooking. And with a recipe (i.e., an algorithm), we took its functional components and separately designed them.
A procedural approach uses the power of abstraction to create a public interface that hides each function’s implementation. This is functional abstraction, and it allows us to think first about a component’s outputs in terms of its inputs and then later worry about the set of computational steps that would turn specific inputs into the desired outputs. And when the public interface created a useful abstraction, we found that we could reuse this function across our program and, hopefully, other programs that we or others might write.
Encapsulation is another benefit of the use of a public interface and hidden implementation. When we hide a function’s implementation, we can test, debug, and even change the function’s body without affecting the sites that call our function. By now, you know that creating a correct program is hard work and that it’s practically impossible to write a correct program in one go. But by using functional abstraction and encapsulation, we can build toward a correct program, one piece at time. And when we miscode a component, we can fix the bugs in that component without causing a domino effect of changes in the rest of our program.
In sum, we use decomposition and functional abstraction to break complex problems into simpler pieces and functional abstraction and encapsulation to code each piece separately.
While a procedural approach to programming works well, it has limits. When the objects that our scripts manipulate are ones built into Python (e.g., strings, ints, and lists) or ones provided in some module built by a Python programmer (e.g., network responses and digital images), focusing on the functions in the recipe works well. However, to solve this chapter’s problem, we are going to need to think about more than its component tasks. We are going to need to build our own objects—that is, some of the ingredients needed in our recipe. In other words, we are going to need to build our own data abstractions.
But have no fear (said the Cat in the Hat). You already have the tools you need to build data abstractions: decomposition, abstraction, and encapsulation! When applied to data (instead of just procedures), you enter the exciting world of object-oriented programming. Python is an object-oriented programming language, which means that it contains features designed to make data abstraction easy.
By the end of this chapter, you will have gained the ability to create recipes and ingredients, which will allow you to solve an unbelievably wide range of complex, real-world problems. Computer scientists think of this pairing as algorithms and data structures. There are many elegant ideas in this space, and through the rest of this act, you’ll get a taste of the rich world of classical algorithms and data structures.[2]
Learning Outcomes
Learn to write a script for goal-directed search and to simulate what you cannot analytically solve. You will understand the difference between procedural and object-oriented programming, and you’ll build algorithms and data structures relevant to finding driving directions from a map. By the chapter’s end, you will be able to do the following:
Describe the components of a formal specification for a goal-directed search problem [design and CS concepts].
Discuss the parallel nature of goal-directed search and finite state machines [design and CS concepts].
Code a random walk across a graph-like data structure with nodes and edges [programming skills].
Argue that the random walk you coded will terminate [CS concepts].
Simulate real-world phenomenon and discuss what you can learn from these simulations [design and CS concepts].
Understand the benefits of object-oriented programming and how it differs from procedural programming [CS concepts].
State the differences between a class and an instance of that class [CS concepts].
Use classes to build your own data structures and inheritance to avoid duplicating code found in related classes [design and programming skills].
Employ Python’s magic methods so that the objects you build look like they were built into Python [programming skills].
Describe the purpose of Python’s
selfconvention [programming skills].Discuss the importance of the representation invariant for writing robust object-oriented code [CS concepts].
Understand how to build a data structure that represents a map and practice building your own classes [programming skills].
Write a script that finds a solution to the driving directions problem and specialize it to perform searches with different algorithmic characteristics, such as breadth-first and depth-first search [design and CS concepts].
Describe the difference between uninformed and informed searches, and state the power (and danger) of heuristics [CS concepts].
Driving directions, a formal specification. Solving a goal-directed search problem, like finding directions from one point on a map to another or cooking a delicious meal, is straightforward once you understand how to model a goal-directed search problem. A good place to start in this modeling is with the problem’s start (or initial) state and its goal (or final) state. These states can be as simple as “I’m here” (start state) and “I want to be there” (goal state), or “I have these ingredients available to me” (start state) and “I want to serve a delicious dinner” (goal state).
Besides these two states, goal-directed search problems have a set of valid actions through which we can manipulate the current state. In the driving context, I have a set of roads (the valid actions) that move me from one location (the current state) to another. In the cooking context, I have a set of kitchen tools and things I can do with them (the valid actions) that change the state of the ingredients.
The many road locations and partially prepared mixtures of ingredients are states, along with our designated start and goal states, that exist in the problem’s complete search space. We might be able to enumerate all these states for a particular goal-directed search problem, but in real applications, we don’t often try. All that matters is that we can distinguish one unique state from another, which is, once again, an encoding problem that translates a collection of real-world things into a computational form.
The solution to a goal-directed search problem is a finite sequence of valid actions that will transform the start state into the goal state. If we cannot find such a sequence, then there is no solution to the problem (e.g., there are no roads that take you from your starting location to your desired goal location).
Parallels with finite state machines. Does this model description remind you of a finite state machine (FSM) that we discussed in Chapter 2? It should! We drew the FSM as a model with nodes, which captured their state information, and directed arrows (also called edges) between these nodes, which were the allowable actions that changed the state represented by the node at the arrow’s tail to that represented by the node at the arrow’s head. The same is true in a goal-directed search model.
While both models have a single start state, they may differ in their number of goal states. You’ll recall that a FSM may have one or more goal states, which together cover the set of valid input strings. In goal-directed search, we typically have a single goal state.
To understand the importance of this difference, you need to remember the purpose of each model. A FSM distinguishes valid strings from invalid ones. These strings are input to the FSM, and they drive the sequence of steps taken by it. At the end of the input string, the FSM reports whether the sequence ended in a goal state.
In goal-directed search, the sequence of steps is not being driven by some external input. Instead, it is the job of our script to search for some sequence of steps that takes us from the start state to the goal state. If, in this search, our code hits the goal state, it stops and reports the sequence of steps it found that moved it from the start state to this goal state.
This fundamental difference in purpose is one of the reasons why we talk about the set of all FSM states and yet say that we’re not often concerned with the full enumeration of states in a goal-directed search problem. In a FSM, when the input veers off a known path toward a goal state, our script can raise an error. In goal-directed search, we don’t know what sequences of steps lead us to the goal state until we find one, and when we find one, we may be uninterested in finding another.
Solutions with specific characteristics. In goal-directed search, there is a lot we don’t know. First, we don’t know, given a particular set of nodes and edges, if it is possible to get from the start state to the goal state. And when there is a solution, we don’t know if there is more than one.
Sometimes, all we care about is finding a solution (or reporting that there isn’t one), and any solution will do just fine. For example, any road that gets me home is a good road. Other times, we may decide to put some constraints on the search problem so that it yields solutions with specific characteristics. For instance, we may not feel that all roads are equally desirable: If we can get home without taking a toll road, that’s what we’d like. A solution with the desired characteristics might not exist, but if one does, our script should return it.
Let’s walk before we drive. Let’s stop talking about what a script that implements goal-directed search should do and start building one. The first thing we need for our problem-to-be-solved is a city map. We can build one with the abstract data type CitySqGrid.[3] We simply tell it how big we would like our square grid of city blocks to be.[4]
1from city import CitySqGrid
2
3not_Boston = CitySqGrid(4)
4print(not_Boston)
You’ll notice that the constructed CitySqGrid object places an s at the city center, which is the starting point for our journey. As for the goal state, let’s imagine that this city is surrounded by a countryside of open fields, and we’d like to spend our day relaxing in one of these fields and playing with my dog Cosmo. We don’t care which field; we simply want out of the city for the day.
The abstract data type CitySqGrid has an attribute that we can use to grab the coordinates of the starting location (CitySqGrid.start), which will be the initial value of this search problem’s current state. Starting there, the loop on lines 13−16 in the code block below allows us to walk Cosmo around the city until we hit our goal state (i.e., until the current state loc is outside the city). CitySqGrid has a method called move that makes it easy to step 'north', 'south', 'east', or 'west'.[5] The method takes our current location (i.e., the current state) and a direction, and it returns a location that becomes our new current state. By the way, in the code block below, we tell CitySqGrid that we want our location on the map to look like Cosmo rather than the boring s character.[6]
1### chap11/walk.py
2from city import CitySqGrid
3
4# Our faithful dog
5Cosmo = '\N{DOG FACE}'
6
7# Build the city and put Cosmo at its center
8nyc = CitySqGrid(4, Cosmo)
9print(nyc)
10
11# Loop that walks Cosmo
12loc = nyc.start
13while loc in nyc:
14 direction = input('Where to? ')
15 loc = nyc.move(loc, direction)
16 print(nyc)
17
18print('Enjoy your day outside the city!')
When we walk Cosmo around this virtual city, move won’t let us walk into a building. Since we don’t live in these buildings, we are not allowed in. What this means is that the CitySqGrid data type is smart enough to know that we can walk only on the streets and not off them. This is important if we want to successfully build a set of driving directions that won’t have our car driving through buildings and fields.
A random walk. Notice that the script walk.py handles a piece of this chapter’s problem: it alerts us when we have reached the goal state (i.e., our walk took us out of the city). What it doesn’t do, without our active help, is search the city for a route to this goal state.
How might we think about a procedure that would get us from the city center to the fields on the outskirts of the city? And for this question, let’s assume that we don’t know anything about the layout of the city except what we see immediately around us. If you’ve spent any time solving mazes as a kid, you probably can think up several different techniques that might work. I’m going to suggest we have the script do the easiest thing possible: for each step the script takes, it randomly chooses a direction.
This is easy to code, as we’ll do in a moment, but first let’s ask: Will a random walk reliably get us out of a city? The answer to this question should be yes. In fact, for any of the techniques you were just imagining, we want the answer to be yes. If not, then there are some maps on which the technique won’t work, and that’s bad if we assured someone that we had a script that always finds a route when one exists.
What we’re talking about here is the proof of correctness we mentioned in chapter 9 as one of the three formal components of an algorithm. Again, this book doesn’t teach you how to create a formal proof of correctness, but we can make a stab at the form of the proof for a random walk.
Will it work? To argue that a random walk will get from the start state to the goal state if a path exists, we might begin by thinking about every type of city layout imaginable and then test our approach against that infinite set of layouts. Yes, that sounds hard and is probably impossible to do.
So instead, good theoreticians and problem-solvers transform these hard questions into their equivalent inverse. For us, this means we need to answer the question: What would need to be true to not allow a random walk to find the goal? If we can rigorously argue that there is nothing keeping us from finding a solution, then we can confidently state that a random walk will reliably get us out of any city.
The argument is fairly simple. We begin by eliminating the case where there is no path from the start to the goal state. Clearly, a random walk would fail in this case; however, no procedure would find a path that doesn’t exist. As such, the real question is: Is it possible for a random walk to never find a solution path when one exists? The answer to this question is no. If a solution path exists and our algorithm can generate that path, there is some probability that it will randomly generate this sequence of steps and achieve our goal.
A short walk, please. The kicker: How long might we have to wait for a script that implements a random walk to find a sequence of steps that end in the goal state? Hard to say, right?
Let’s again transform the question. What structure in a map might make it take an unbounded amount of time to find the solution? The answer might have popped into your mind. A loop!
In reality, we don’t even need a loop in the roads to have a situation where our random walk takes forever. The algorithm might repeatedly generate a step west followed by a step east, and then west, then east, west, east…. Even in a city with a single road that leads from the city center to a field on the outskirts, this possible sequence of steps would cause our algorithm to never return.
No loops. We can eliminate solutions that take a really long time (and a lot of space) to generate by eliminating loops from our search space.
Fig. 30 Starting in the center of the city and then following the eight-step path 'eennwwss' puts us exactly back where we started. We can remove any such loops from the space of paths we should search because they don’t advance us toward our goal.#
For example, a solution that heads straight east in our city with a square grid is a solution to our problem. One that heads straight east, but loops around the first block one time before continuing to proceed east, is another solution. However, the first eight steps of the sequence 'eennwwsseeee' put us directly where the sequence 'eeee' also starts (i.e., the start state, as illustrated in Figure 30). If an algorithm has already explored a path that starts at the current state and returns to that state, repeating this path clearly won’t advance us toward a solution. This means that we can eliminate loops in our maps and not worry that we will miss finding a solution.
Only visit new spots. A necessary condition of looping is that we must visit the same location more than once. If we create a random walk algorithm that is not allowed to visit a location more than once, we can guarantee that the algorithm will either find a (loop-free) solution or get caught in a “dead end.” A walk ends in a dead end if the algorithm cannot find a new location to visit from its current location. For example, in our previous example, the first seven steps of the sequence (i.e., 'eennwwss') leaves us without a valid location to visit next that hasn’t already been visited.
If you think about it, no run of this algorithm will take more steps than there are locations in the map. It may still take many random walks to find a solution, but no single random walk will take infinite time.
A dog walk. Let’s implement this random-walk algorithm, and since my dog Cosmo is much better at a random walk than I am, we will simulate him wandering around a city. His nose will tell him if he is about to repeat a location he’s already visited, which will guarantee that our algorithm doesn’t fall into any wasteful loops. The function dogwalk in dogwalk.py implements this behavior.
You Try It
Run python3 dogwalk.py. The first printing of the city displays Cosmo at the start position. The second illustrates the random path he took (i.e., the asterisk characters mark the path[7]). Run it several times until you’ve seen that he can get both outside the city and caught in a dead end.
1### chap11/dogwalk.py
2from city import CitySqGrid
3import random
4
5# Our faithful dog and the scent he smells
6Cosmo = '\N{DOG FACE}'
7EXPLORED = '\033[34m*\033[0m' # blue *
8
9def dogwalk(my_city):
10 """Given a city of type CitySqGrid, take a random walk
11 and return True if goal successfully met. The
12 successful path is marked in the city object."""
13 # Set the current state
14 cur_loc = my_city.start
15
16 while cur_loc in my_city:
17 # Where to? Well, what steps are possible?
18 moves = my_city.possible_moves(cur_loc, EXPLORED)
19 # print(f'DEBUG: cur_loc = {cur_loc}; moves = {moves}')
20
21 if len(moves) == 0:
22 return False # dead end!
23
24 # Randomly pick a possible move and make it
25 a_move = random.choice(moves)
26 next_loc = my_city.move(cur_loc, a_move)
27
28 # Leave a scent at current loc
29 my_city.mark(cur_loc, EXPLORED)
30
31 # Update current state
32 cur_loc = next_loc
33
34 # The random path was successful!
35 return True
Terminology
It is worth reviewing the terminology that I first mentioned in Chapter 1. In the function dogwalk, my_city is an object, and this object has a set of attributes associated with it. For example, the attribute start is a data attribute (i.e., it names a data object) and the attributes possible_moves, move, and mark are function attributes (also called methods that we call like a function).
The algorithm in the function dogwalk builds on that in walk.py. It sets the current state (i.e., cur_loc) to the starting location in the city, and then it falls into a while-loop that iterates until this current state matches our goal. Inside the loop, we call my_city.possible_moves, which returns the list of possible moves we can make from our current location. This method’s second argument is the character that we use to mark already-visited locations in the city; these marks are made on line 29. With a valid list of possible moves, the algorithm randomly picks one and moves there (lines 25−26). Of course, it can make a move only if Cosmo isn’t at a dead end, which is the check on lines 21−22. Finally, line 32 prepares the algorithm to repeat these actions with the new location where Cosmo moved.
Here’s the main function in dogwalk.py that builds a small, regular city and then has Cosmo go for a walk.
36### chap11/dogwalk.py
37def main():
38 print('\nBuilding a city with a 4x4 square grid')
39 nyc = CitySqGrid(4, Cosmo)
40 print(nyc)
41
42 # Cosmo walks himself
43 success = dogwalk(nyc)
44 print(nyc)
45 if success:
46 print(f'Cosmo is frolicking in the fields!')
47 else:
48 print(f'Cosmo hit a dead-end.')
The algorithm in dogwalk illustrates the core of goal-directed search. It’s not quite the algorithm we want for our driving directions problem, since it gets caught in dead ends when there exist valid paths from the start location to the goal location. We’ll fix this issue later in this chapter. But first, I want to show you how to use dogwalk to reveal interesting facts about our physical world.
Simulation. Consider this question: When Cosmo takes himself on a walk, how likely are we to find him wandering around in the fields instead of being trapped somewhere in the city? Using dogwalk, we can learn that the answer to this question depends on the size of the city. We simply review the outcomes of many random walks, and this empirical process gives us an idea of a likelihood.
Let’s implement this process. The next code block builds a self-avoiding random walk simulation from dogwalk.py’s main routine.[8] You tell the sim function how big to make the city and how many trials to run. With a CitySqGrid object of the specified size, the function repeatedly[9] invokes dogwalk and keeps track of how many of times Cosmo hit a dead end. When the number of trials is complete, it computes the percentage of dead-end runs.
2### chap11/sim.py
3from city import CitySqGrid
4from dogwalk import dogwalk, Cosmo
5
6def sim(blocks, trials, verbose):
7 # Initialize the metric of interest
8 dead_ends = 0
9
10 # Build the specified city
11 my_city = CitySqGrid(blocks, Cosmo)
12 if verbose:
13 print(f'\nBuilding a {blocks}x{blocks} city')
14 print(my_city)
15
16 for _ in range(trials):
17 # Reset the city before each trial
18 my_city.reset()
19
20 # Run, record, and print the trial
21 success = dogwalk(my_city)
22 if not success:
23 dead_ends += 1
24 if verbose:
25 print(my_city)
26
27 # Print the percentage of trials ending in dead ends
28 print(f'{100 * dead_ends // trials}% dead ends')
You Try It
Run
sim.pyseveral times with a block size of 4 and trials equal to 20 (i.e., runpython3 sim.py 4 20). It will probably report that approximately 5−15 percent of Cosmo’s walks ended in dead ends.Now double the size of the city and run the simulation again several times. This time it will probably report that 25−40 percent ended in a dead end.
Finally, double the city size once more. The likelihood of a walk ending in a dead end has jumped again, to somewhere around 80−90 percent.
Our conclusion: In a small city, we should look for Cosmo in the fields; in a big city, he’s probably still somewhere inside it. This simulation taught us a fact about our world.
A self-avoiding random walk is used to simulate an aspect of the world that no one knows how to model analytically. It is an important simulation technique in numerous areas of math, science, and engineering. For example, it helps biologists learn about the topological behavior of proteins, which is an important challenge without an analytical solution.
Object-oriented programming. Let’s return to our driving directions problem. In addition to the problem that dogwalk.py may print a path that is a dead end, this script works with regular city grids. We want it to produce driving directions for any roadmap. In other words, we need a data type that is more general than what we have with CitySqGrid. Where can we find such a data type? Well, where did this CitySqGrid data type come from?
The answer is that I built it. You won’t find CitySqGrid in the Python language documentation or in a Python module that some generous soul published. Was it obvious to you at any point that it was something I wrote? Hopefully not, and this is the beauty of coding in a well-designed, object-oriented language. We’ve been using instances (e.g., my_city) of CitySqGrid, and as long as we understood its interface and behavior (i.e., its abstraction), we happily used it to solve our problem as if the data type was a part of Python.
This is power of object-oriented (OO) programming, which uses data abstractions as well as procedural abstractions to simplify problem solving. With a facility to create data abstractions, we are freed from using just the data types that Python or some Python library provides.
Tip
At first, OO programming may feel overwhelming because it comes with a boatload of syntax and jargon. Even I find the OO terminology to be intimidating and confusing. But there’s nothing to fear here because you have been using the OO approach from this book’s start. Everything you manipulate in Python is an object, even what feels primitive and simple, like integers and strings. I’ll introduce you to the basics of OO programming, and if you’d like to learn more, you might want to read Chapter 10 in John Guttag’s Introduction to Computation and Programming Using Python.[10]
Classes. If you look at line 4 in the module city.py, you’ll see the following:
3### chap11/city.py
4class CitySqGrid(maze.Maze):
This is the class definition for CitySqGrid, and classes are how we implement data abstraction in Python. In other words, through the Python keyword class, you define and implement new data types. In a bit, I’ll explain what goes in the parentheses when you define a new data type.
Like a function definition, a class definition defines a data type’s interface and makes explicit its implementation. When we learned about functions and their definitions in Chapter 3, it was easy to identify the public interface from the private implementation. The same separation exists with classes, but it is harder to see, especially in Python.[11] If your new data type is anything but trivial, it becomes very hard to understand how to use it by simply reading the class’s definition. This means that docstrings and comments become extremely important.
Tip
I have described the interface for CitySqGrid (i.e., its abstraction as seen through its data attributes and methods) in a docstring at the top of its class definition. I further adopt the convention of following the docstring with a comment that is meant not to help users of the data type but those who want to modify its implementation. Follow this convention or imagine your own—just give those who will use your data type some clear way to understand what’s in its interface and what are implementation details.
While I’ll continue to make reference to the CitySqGrid class, it is too complicated to use as an understandable first example. Instead, I’ll teach you how to build your own class by creating a new data type, called Pin, that allows us to add Google-Maps-like pins[12] to the CitySqGrid maps we used in walk.py.
8### chap11/pin.py
9class Pin(object):
10 """Abstraction: A Pin object is a mark at a map location loc
11 with a name, descriptive note, and a ranking of 0-5 stars.
12 These names are all instance attributes.
13
14 instance.icon: The pins displayed icon, which depends upon
15 the pin's number of stars.
16
17 distance(location): Given a (x,y) location, this method
18 computes and returns the as-the-crow-flies distance from
19 this pin's location, but only if this pin is highly rated.
20
21 __str__(): Converts the pin into a string.
22 """
23 # ... implementation of the Pin class follows ...
You Try It
In the chapter’s GitHub repository, you’ll find the script wander.py, which adds pins to the functionality of walk.py. Run python3 wander.py, and it will print a 6×6 square city with pins and Cosmo ready for his walk. The pins are the green hearts and red x-marks on buildings. Walk Cosmo around the city as you did in walk.py, or type a c to teleport him to the nearest green heart (i.e., one of his highly rated places). If you type a q or step outside the city, your wanderings come to an end.
Building an instance. The function main in wander.py builds a list of pins (lines 68−73) and then iterates over this list to mark the pin locations in the city it built (lines 65 and 74−75).
62### chap11/wander.py
63def main():
64 # Build the city and put Cosmo at its center
65 nyc = CitySqGrid(6, Cosmo)
66
67 # Add Cosmo's favorite pins to the city map
68 pins = [
69 Pin((3,11), "Park", "Lots of squirrels", 5),
70 Pin((7,9), "Fire Hydrant", "Many good smells", 4),
71 Pin((5,3), "Cat", "Not a nice cat!", 1),
72 Pin((9,1), "Bakery", "Free dog treats!", 5)
73 ]
74 for pin in pins:
75 nyc.mark(pin.loc, pin.icon)
76
77 print(nyc)
78
79 wander(nyc, pins)
80
81 print('Thanks for the fun walk!')
Line 69 creates an object (also called an instance) of type Pin. If you think about Python’s built-in data types, like integers, strings, and lists, there is special syntax in the language to handle the creation of objects of these types. For example, when we type a number without a decimal point, the Python interpreter knows we want to create an integer object with that number as its value. For strings, we put the value in a matching pair of quote characters. For lists, we use square brackets.
1# Examples of creating an instance of a built-in object. We get to
2# use special syntax in each of these cases.
3an_int = 0
4an_empty_string = ''
5an_empty_list = []
6print(an_int, an_empty_string, an_empty_list)
But we can also build instances of these built-in data types by directly invoking their constructors. The form of a constructor is the class name (i.e., its type) followed by a pair of parentheses. The result of a call to a constructor is a newly minted object of that type.
1# The same examples as the last code block, except we're creating
2# instance of built-in object using the type's constructor.
3an_int = int() # constructor default is the value 0
4an_empty_string = str() # constructor default is an empty string
5an_empty_list = list() # constructor default is an empty list
6print(an_int, an_empty_string, an_empty_list)
It is possible to initialize these objects to values other than their defaults by passing an initialization value in the constructor call.
1# With some initialization values
2an_int = int(0)
3a_string = str(an_int)
4a_list = list(a_string)
5print(an_int, a_string, a_list)
This constructor syntax is how I created, in wander.py on line 65, a 6×6 instance of CitySqGrid with a dog-face character at its center (named nyc). It is also how I created a Pin object on line 69.
This creation takes two steps. First, the interpreter grabs a raw piece of our computer’s memory that’s large enough to hold all the instance’s attributes (i.e., all the data specific to this object). By raw, I mean that none of this memory is initialized in such a manner that an object acts like an instance of CitySqGrid or Pin. Initialization, the second step, is the job of a class’s __init__ method.[13]
22### chap11/pin.py
23 def __init__(self, loc, name, note, stars):
24 self.loc = loc
25 self.name = name
26 self.note = note
27
28 assert stars >= 0 and stars <= 5, "Invalid number of stars"
29 self.stars = stars
30
31 if self.stars >= 3:
32 self.icon = green_heart
33 else:
34 self.icon = red_x
An __init__ constructor is just a function defined in a class’s namespace[14] (i.e., you indent it under the class definition). Comparing line 23 above with lines 69−72 in wander.py at the start of this section, the Pin constructor’s last four formal parameters match the four actual parameters provided in the constructor call. Unexpectedly, the interface definition also includes the name self as the function’s first formal parameter.
Self and instance attributes. Every method definition must contain this additional formal parameter called self[15] (and it must be listed first). The self parameter gives you a way to distinguish data attributes belonging to an instance (called instance attributes) from those shared across all instances (called class attributes). When we call the Pin constructor on line 69, it returns a Pin object with location (3,11), name "Park", and so forth. The constructor stores the first two parameter values in the two instance attributes self.loc and self.name (on lines 24 and 25 of pin.py). These values[16] take up memory space in the Pin object that is the first element of the pins list. The Pin object in the list’s second element has different values for its instance attributes.
Although we won’t use them in this book, you can also create class attributes (also called class variables). With a class variable, you don’t have that variable for each instance but a single variable that is shared by every instance of the class. If, for example, the name note was a class variable, you’d write Pin.note rather than self.note in a class method (i.e., you replace self with the class name as the namespace).[17]
Finally, be careful not to confuse instance variables with local variables. The name loc in Pin.__init__ is a local variable. If you look at the implementation of CitySqGrid.__init__, you’ll see that I create the local variable row1 to name an intermediate computation. These local names exist only while the method is running. Instance variables, on the other hand, are names with values that we want to persist between method executions.
Tip
Knowing whether you need to prepend self to a name is tricky, and it will take some time for you to naturally know when and when not to use it. Until you do, I suggest you pause as you write a variable name in a class method and ask yourself, “Am I trying to access an attribute of a particular instance of this abstract data type (i.e., class), or is this just a local variable that is helping me to complete the work of this method?” You need self in the first case and not in the second.
As you can see in the function body of Pin.__init__ (lines 24−34), instance variables are sprinkled throughout the constructor’s implementation. If you explain your data type’s abstraction in a docstring, a user won’t have to read through your constructor to try to understand what attributes you’ve made available.
Methods. In addition to __init__, the class definition in pin.py defines two other methods. The distance method computes the as-the-crow-flies distance between the instance variable self.loc and the method’s formal parameter loc. I use this method in wander.py (line 41) to have Cosmo jump from his current location in my_city to the closest, highly rated pin.
38### chap11/pin.py
39 def distance(self, loc):
40 if self.stars >= 3:
41 return abs(math.dist(self.loc,loc))
42 else:
43 return MAX_DISTANCE
34### chap11/wander.py
35 elif cmd == 'c':
36 best_loc = NO_LOC # not a valid location
37 best_distance = MAX_DISTANCE
38
39 # Find the closest highly-rated pin
40 for pin in pins:
41 dist = pin.distance(cur_loc)
42 if dist < best_distance:
43 best_loc = pin.loc
44 best_distance = dist
45
46 assert best_loc != NO_LOC, "Failed to find a pin"
47
48 # Teleport to within one step, which requires me to erase
49 # the character from the cur_loc.
50 character = my_city.get_mark(cur_loc)
51 my_city.mark(cur_loc, ' ')
52 cur_loc = (best_loc[0] - 1, best_loc[1] - 1)
53 my_city.mark(cur_loc, character)
54 direction = 'n'
The method distance could have been a function outside the namespace of the class Pin, but in OO programming, your goal is to put functions that operate on a class’s instances in the class definition. In this way, the class definition bundles together the data (as attributes) and functions (as methods) that work together on a particular abstraction (i.e., maps and pins in our running examples). This bundling (called encapsulation) helps you (the class designer) make sure that a class’s data are properly managed, as I explain further in the next section. As the scripts you write grow in size, you’ll also find that this encapsulation helps to organize your code in a manner that makes it easier to understand and maintain.
Representation invariant. As we model the world in our scripts, we’re not just manipulating data but trying to build useful abstractions. In a class, the __init__ method is not only responsible for initializing a new instance but also for creating a valid representation of a class’s object. For example, our pins have a star rating, and this rating should be between 0 and 5 inclusive. The Pin.__init__ method contains code (lines 28−29) that guarantees a new Pin object adheres to this representation invariant.
While the __init__ method establishes the representation invariant, the other class methods are expected to maintain it. The Pin.distance method does because it doesn’t change any of the instance variables. A more interesting example is CitySqGrid.reset, which makes sure when we reset a CitySqGrid object back to its initial state that we put the character (e.g., the Cosmo dog emoji) back at the grid’s center (see line 67 in city.py).
Ensuring that your class’s methods never break the representation invariant is one goal, but you should also design your class so that its users aren’t able to break it. My Pin class does not fully protect its representation invariant because a user could write a value to a_pin_object.stars outside the expected range. We could fix this problem by following the setters and getters pattern in OO programming, which gives the class designer control of a user’s access to the class’s attributes.[18]
Magic methods. The last undiscussed method in the Pin class is __str__. Like __init__ and unlike distance, this method’s name starts and ends with two underscore characters. Methods that start and end with two underscores are called magic methods in Python, and they are what allow you to treat an instance of your class just like Python’s own built-in types.[19]
35### chap11/pin.py
36 def __str__(self):
37 return f"{self.name} at {self.loc} rated {self.stars}" + '\u2605'
The method __str__ should always return a string. As the data type’s designer, I can return any string I like, and I’ve chosen to return a simple description of the Pin object using a few of its attributes. This is a magic method because the interpreter looks for it when a Pin object is used where the interpreter expects a string object. For example, the input parameters to print are expected to be strings, and when we pass a Pin object as a parameter to print, the Python interpreter looks for this specific magic method and, if it finds it, uses it. The main function in pin.py runs a few tests on the Pin class and uses CitySqGrid along the way; it demonstrates how easy a __str__ method makes printing the instances of classes we define.
48### chap11/pin.py
49def main():
50 # Our faithful dog
51 Cosmo = '\N{DOG FACE}'
52
53 # Build a city
54 nyc = CitySqGrid(6, Cosmo)
55
56 # Create some pins and keep track of them in a list
57 pins = [
58 Pin((3,11), "Park", "Lots of squirrels", 5),
59 Pin((7,9), "Fire Hydrant", "Many good smells", 4),
60 Pin((5,3), "Cat", "Not a nice cat!", 1),
61 ]
62
63 # Add each pin in pins to the city map
64 for pin in pins:
65 print(f'Adding {pin}')
66 nyc.mark(pin.loc, pin.icon)
67
68 print(nyc)
You Try It
Use the dir command to see what attributes are in the list namespace: dir(list). You’ll find __str__. Now you know how we’ve been able to print so many Python objects by just passing them as parameters to print.
The docstring on CitySqGrid describes several other magic methods that we’ve used. For example, the __contains__ method allows us to use the Python operator in with a CitySqGrid. This method requires a parameter, which is a location in the city grid we’re asking about. It becomes the value to the left of the in operator, and the CitySqGrid instance we want to check is to the right. In other words, the Python interpreter changes the second code block below into the first one.
loc = (1, 1)
nyc.__contains__(loc)
loc = (1, 1)
loc in nyc
The key idea here is that, when we define our own data type, we want to use it like those built into Python.
Tip
Implement as many of the Python magic methods that make sense for your class. It will make it easier for you and others to use your data type.
Building on others. It’s finally time to explain what’s in the parentheses on the class definition line. The Pin class definition begins with class Pin(object) and CitySqGrid with class CitySqGrid(maze.Maze). I built both these data types, but I didn’t design them from scratch. I built each as a specialized kind of a more general data type. This more general data type is what you put in the parentheses of the class definition.
The Pin class builds on a class called object, which is a class at the root of the Python object hierarchy. Every object of a built-in Python data type is also an object of type object. By saying that Pin is derived from object, I’m saying that I want Pin objects to be Python objects. Similarly, every instance of CitySqGrid is an instance of the data type called Maze, which is itself an instance of object (as seen in maze.py). Object-oriented enthusiasts call CitySqGrid a subclass of Maze. As a subclass, CitySqGrid inherits the attributes of Maze.
Terminology
Along with the term subclass, you will hear the complementary term superclass. Maze is the superclass of CitySqGrid, and it shares its attributes with all its subclasses.
It’s good that a subclass inherits the attributes of its superclass because, if you look in city.py at CitySqGrid’s class definition, you’ll find only two method definitions: __init__ and reset. This is despite the fact that CitySqGrid objects use many other methods (e.g., in wander.py, we used mark, get_mark, __str__, and __contains__).
The maze class is quite long, and I don’t expect you to read through it in detail. But you should understand what it means when you see some methods (e.g., __str__) in the superclass (e.g., Maze) but not the subclass (e.g., CitySqGrid). It means that objects of the subclass act just like objects of the superclass for the purposes of these methods. For example, converting a CitySqGrid object into a string follows the same procedure as converting a Maze object into one.
There are only two methods in CitySqGrid that override the similarly named methods in Maze. These CitySqGrid methods exist because they need to do something different for CitySqGrid objects than what their namesakes in Maze do. Take CitySqGrid.reset; it wants to do everything in Maze.reset (as seen on line 64) plus the positioning of the character at the start location (line 67).
61### chap11/city.py
62 def reset(self):
63 """Resets all cell contents to their original state"""
64 maze.Maze.reset(self)
65
66 # Reset the start point with our character
67 self.mark(self.start, self.character)
In general, it’s fine for a superclass method to operate on instances of a subclass if the methods maintain the subclass’s representation invariant. If they don’t, then you should override them by redefining those methods in the subclass.
Terminology
You will find methods in the Maze class with names that start with a double underscore but do not end with them. By convention, these are helper functions. OO programming not only encapsulates the attributes and methods of a data type in a class statement, but it allows you to use all the helpful aspects of procedural programming within this statement. For example, turning a Maze object into its ASCII image involves a row-by-row generation of ASCII characters. It is easier to implement this procedure by factoring out the work done for each row into a method called __str_row and then having __str__ repeatedly call this helper function. However, this is an implementation detail, and I want it hidden from those using the data type. In Python, this hiding is done with a naming convention; other programming languages have keyword mechanisms for making certain attributes of a class private to the implementation of the class. If a piece of Python code outside the class definition calls a double-underscore-leading method at runtime, the Python3 interpreter will raise an AttributeError.
General maps. The Maze class is the abstract data type that we need to build a general map and on which we’ll design a goal-directed search algorithm that produces driving directions. We’re familiar with its interface from working with CitySqGrid objects. The map I’ll use in my examples is specified by the two configuration strings: MAZE_map and MAZE_map_endpts, which are defined in maze.py. When printed, these strings produce the map in Figure 31.[20]
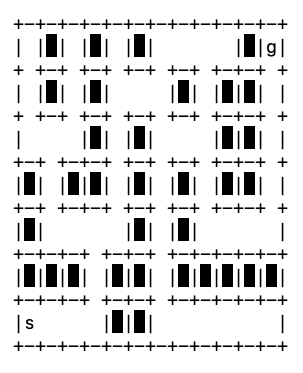
Fig. 31 The map produced by the configuration strings MAZE_map and MAZE_map_endpts in maze.py. We’ll start at the location marked with an s and follow the roads, which are the empty squares. Our goal is the square with the g.#
Keeping track. Now that we have a digital representation of a map and an interface that allows us to move around it, we can finally write the script that will find a set of driving directions from our start location (s) to our goal location (g). This function will do much of what the function dogwalk.py did, and so we’ll start with it. However, when we ask for driving directions, we’re not interested in seeing every path that the code explores, especially not the paths that end in dead ends. Our problem specification says that our script should execute until it finds a solution or determines that there is no path from start to goal. If you like solving printed mazes, you already know how to do this: our function will need to keep track of the parts of the map it has explored and those places on the map it can reach from start but hasn’t yet explored. By tracking these unexplored places, our script can restart its search at one of them when its current search path ends in a dead end. And it will know that the map does not contain a route from start to goal if it ever reaches a point when there are no locations left to explore.
The function search in directions0.py implements this algorithm, starting with the frame of dogwalk. You’ll recognize the initialization of the start location (line 10) and the while-loop that continues until it hits the goal location (line 16). In the loop, it gathers possible next steps from the current location (line 18) and selects one (line 38). If there is no possible next step, it reports that there’s no path from start to goal to be found in the input map (lines 33−35).
1### chap11/directions0.py
2import maze
3
4# Marks for map, which use color codes for terminal printing
5EXPLORED = '\033[34m*\033[0m' # blue *
6FRONTIER = '\033[32mf\033[0m' # green f
7
8def search(my_map):
9 # Set the current state and mark the map location explored
10 cur_loc = my_map.start
11 my_map.mark(cur_loc, EXPLORED)
12
13 # Build a list on which to keep known but unexplored locations
14 frontier = []
15
16 while cur_loc != my_map.goal: # search loop
17 # What unexplored next steps are possible?
18 moves = my_map.possible_moves(cur_loc, EXPLORED)
19
20 # Add moves not already on the frontier to the frontier
21 for a_move in moves:
22 loc = my_map.simulate_move(cur_loc, a_move)
23 if loc not in frontier:
24 frontier.append(loc)
25 my_map.mark(loc, FRONTIER)
26
27 # DEBUG: Uncomment to watch the frontier grow
28 # print(my_map)
29 # print(f'DEBUG: cur_loc = {cur_loc}; moves = {moves}')
30 # print(f'frontier = {frontier}')
31 # input('Ready to move on? ')
32
33 if len(frontier) == 0:
34 print('No solution')
35 return
36
37 # Choose a location from the frontier to explore next
38 cur_loc = frontier.pop()
39 my_map.mark(cur_loc, EXPLORED)
40
41 print('Found a solution')
42 my_map.print()
43 return
The new bit is the addition of a frontier list (line 14), which keeps track of the possible moves not yet chosen (line 24). Remember that the function dogwalk threw these other possibilities away. We now keep them so that the function ends when there truly are no other possible paths to explore (line 33).
There is one tricky aspect to the maintenance of the frontier list. We might get to a location along multiple paths from the start location (see Figure 32 for such an example). We should add such locations to our frontier list only once. Line 23 in directions0.py ensures that the algorithm abides by this condition.
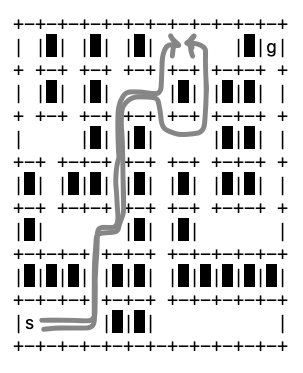
Fig. 32 Two paths from start that reach location (1,8). Our script should add this location to the frontier list only once.#
You might also notice that we pop an unexplored location off the frontier list (line 38) instead of using random.choice as we did in dogwalk. You can think of this pop as making a random choice because we aren’t paying attention to what’s at the end of list. Later in this chapter, I’ll explain how a different choice affects the running of the search.
You Try It
Uncomment lines 28−31 and then run python3 directions0.py. In each loop iteration, it pauses and prints the map so that you can watch the algorithm explore the map and manage the frontier. Hit enter when you want the algorithm to continue. When you’re done, re-comment these lines and rerun the script.
Remembering how we got there. Our function search finds a path in my_map from the start location to the goal location, but this path is lost in the sea of paths that ended in dead ends. We need to add functionality to our algorithm that lets it pull this desired path out from the others. The challenge is that we won’t know which steps are in the desired path until search encounters the goal. Until that point, we must have it record the actions from all its explorations. Visually, search needs to record the actions it took along the six gray paths in Figure 33, which didn’t reach the goal, as well as the single black path, which did.
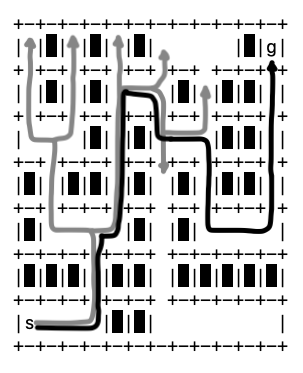
Fig. 33 The seven paths explored during the execution of search on our example map.#
Tip
Recording paths like these (i.e., moving from one state to another by taking some action) is a pattern that you’ll see in many computational problems.
We record these paths by building a data structure that mimics the treelike structure you see in Figure 33. In this figure, all paths take the same first five actions (i.e., go east three steps then north two). At location (4,3), two of the gray paths head west and the rest of the paths, including our desired black one, head east. These first five actions represent the trunk of an imagined tree, and location (4,3) represents the first branching of the tree.
We can digitally represent this tree by connecting together a series of notes to ourselves, each of which we’ll call a TreeNote. In these notes, the search function will record (at least):
a state (which in our problem this is a map location); and
the action (i.e., a driving direction) taken by our
searchfunction that is connected to the recorded state.
I cryptically described the noted action because we have a choice: Do we want to record the action that search took from the state in the note, or would it be better to record the action search took to get to that state? Well, which do we need to solve the problem in front of us? Which will help distinguish the black path from the gray ones in Figure 33? To answer this question, think about what you want to know when search finds the goal.
There’s nowhere to go from the goal, since search has found where we wanted to go, but it needs to know how it got there. So it needs to record the previous action that got it to the current location. And to walk all the way back from goal to start, it will want a chain of notes it can follow. Using Python classes, the data structure I’m describing would look as follows:
8### chap11/directions-dfs.py
9class TreeNote():
10 def __init__(self, state, parent, action):
11 self.state = state # current location
12 self.parent = parent # previous note in path
13 self.action = action # action that got us to this location
As an example of this chaining, the search function would start by creating a note for the start location, which it creates by calling the TreeNote constructor with parameters that say there is no parent note and no action that got us to start—that is, TreeNote((1,1), None, None). From start, the only move to make in our example map is east, and the constructor call for the next location is: TreeNote((2,1), ???, 'east'), where I’ve left the parent parameter unspecified. What is it supposed to be? Right—the note (i.e., the name of the TreeNote) created at start. With the proceeding note in our current note, we’ll be able to find the location that preceded the goal and, from it, the location before it, all the way back to the start.
Interestingly, branching points present no difficulties when proceeding in a tree from a leaf (i.e., the arrow heads in Figure 33) to the root (i.e., the start location). A branching location is the parent to all paths that emanate from this point. This means, if we start at the end of the black path (i.e., the goal), search can easily follow the notes it created directly back to start, and to produce driving directions, it simply reverses the list of actions it encounters as it visits each parent from goal to start.
You Try It
Don’t just read about the data structure the next script (directions-dfs.py) builds with instances of TreeNote. Uncomment the debugging statements on lines 37−40, watch each step of the search, and draw your own picture of the TreeNote objects that are created and how they are linked together.
The solution. We have all the components needed to solve our problem, and we just have to implement them. Once we’ve defined our TreeNote class, we use it where needed. For example, in directions0.py, we stored unexplored map locations in the frontier list, but now when we pop from this list, we are going to want to have access to the TreeNote that goes with it. It is needed to build the notes for the unexplored locations reachable from that TreeNote’s location. If you think about this for a bit, you’ll realize that we’ll want to store TreeNote objects on the frontier list. A complete solution for search is shown below.
1### chap11/directions-dfs.py
2import maze
3
4# Marks for map, which use color codes for terminal printing
5EXPLORED = '\033[34m*\033[0m' # blue *
6FRONTIER = '\033[32mf\033[0m' # green f
7
8# Keep track of the tree of explored paths
9class TreeNote():
10 def __init__(self, state, parent, action):
11 self.state = state # current location
12 self.parent = parent # previous note in path
13 self.action = action # action that got us to this location
14
15def search(my_map):
16 # Set the current state and mark the map location explored
17 cur_loc = my_map.start
18 my_map.mark(cur_loc, EXPLORED)
19 cur_note = TreeNote(cur_loc, None, None)
20
21 # Build a list on which to keep known but unexplored locations
22 frontier = []
23
24 while cur_loc != my_map.goal: # search loop
25 # What unexplored next steps are possible?
26 moves = my_map.possible_moves(cur_loc, EXPLORED)
27
28 # Add moves not already on the frontier to the frontier
29 for a_move in moves:
30 loc = my_map.simulate_move(cur_loc, a_move)
31 if loc not in frontier:
32 new_note = TreeNote(loc, cur_note, a_move)
33 frontier.append(new_note)
34 my_map.mark(loc, FRONTIER)
35
36 # DEBUG: Uncomment to watch the frontier grow
37 # print(my_map)
38 # print(f'DEBUG: cur_loc = {cur_loc}; moves = {moves}')
39 # print(f'DEBUG: frontier = {[note.state for note in frontier]}')
40 # input('Ready to move on? ')
41
42 if len(frontier) == 0:
43 print('No solution')
44 return
45
46 # Choose a note from the frontier to explore next
47 cur_note = frontier.pop()
48 cur_loc = cur_note.state
49 my_map.mark(cur_loc, EXPLORED)
50
51 # Follow the parent links from cur_note to create
52 # the actual driving directions
53 ddirections = [cur_note]
54 while cur_note.parent: # while parent exists
55 cur_note = cur_note.parent
56 ddirections.insert(0, cur_note)
57
58 # Print out the driving directions
59 print('## Solution ##')
60 print(f'Starting at {ddirections[0].state}')
61 ddirections.pop(0)
62 for n in ddirections:
63 print(f'Go {n.action} then')
64 print('Arrive at your goal')
65 return
If you compare this code with directions0.py, you’ll see that the only differences are the creation of notes (lines 19 and 32), the maintenance of them on the frontier list (lines 33 and 47), and the determination and printing of the final driving directions (lines 51−64).
When search encounters the goal and the while-loop ends, the interpreter begins execution of the code on lines 51−64. These are the lines that use our notes to create the driving directions we desire. The first block (lines 53−56) starts with cur_note, which is the goal location when the while-loop exits, and builds a list (called ddirections) that reverses the order in which the loop visits the notes. The second block (lines 59−64) uses ddirections to print the actions in human-readable form. The only trickiness is on line 61, where we must remember to remove the note corresponding to the start location, which has no stored action.
You Try It
Run python3 directions-dfs.py. It prints the driving directions we desire!
Depth-first search (DFS). The search algorithm in directions-dfs.py is a depth-first search.
You Try It
Again, uncomment lines 37−40 in directions-dfs.py and run python3 directions-dfs.py. It prints a sequence of maps corresponding to each step the function search makes. When you review these maps in order, you’ll notice that search goes down a road as far as it can before backing up and trying a different road. When it encounters an intersection, it chooses a direction through that intersection and keeps going.
This behavior is clearly not the only thing our search algorithm could have done, and if we want to do something different, we need to understand what caused this behavior. The answer is amazingly simple: the way in which we add elements to and remove them from the frontier list. The current code does the following:
When we find a new unexplored location, we append it to the end of the frontier list (line 33).
When we go to explore a new location, we pop one off the end of the frontier list (line 47). In Python,
popwith no arguments removes the last item from the list.
Computer scientists like to talk about this behavior as “last-in, first-out” and imagine it as operating like a stack (e.g., a stack of plates): The last one added to the stack is the first one taken off.
What’s good about this approach? Well, if we’re lucky, the first path we explore might lead to the goal state, and even if not, the approach can be very fast in finding a solution when there are many possible solutions. On the other hand, when there are many paths to the goal, this approach just takes the first it finds. There’s no guarantee that our DFS solution is the shortest path to the goal.
Breadth-first search (BFS). But what if we’re interested in finding the shortest path from start to goal (i.e., let’s change our specification). Can we change the way search operates to guarantee that it returns the shortest path, if one exists? We can, and what’s even more amazing is that it requires only a single character change!
You Try It
The only substantial difference between directions-dfs.py and directions-bfs.py is the addition of 0 as the parameter passed to pop (line 47). Line 1 is also different, but that change in the comment doesn’t affect the script’s behavior. Now uncomment lines 37−40 in directions-bfs.py and run it. Contrast how it explores the maze with what you saw when running directions-dfs.py.
Both versions of search place new unexplored locations at the end of the frontier list; they differ only in how they take unexplored locations from the frontier list. DFS takes from the end. Breadth-first search (BFS) takes from the front. Instead of “last-in, first-out” as under DFS, BFS manages the frontier in a “first-in, first-out” manner, which is what computer scientists called a queue. Imagine the line that queues up to check out at a grocery store.
When you watched the BFS script operate, you saw the search expand in all directions at the same rate. In other words, no explored path was more than one step longer than any other path. This means that search will find the shortest path (or technically, one of the shortest) from start to goal before any longer path. This approach is guaranteed to find the shortest path, but at the cost of searching methodically along every path.
You Try It
If you take the time to figure out how the configuration strings work in maze.py, design your own map and reference it on line 70 in the DFS and BFS scripts. You should find that these fairly short scripts are impressively robust!
Informed searches. Both DFS and BFS are called uninformed searches because they don’t use any information about the problem except what they gleam from their own explorations. This means that you can directly use these algorithms on any goal-directed search problem. You just need to encode your problem in a data structure comprising interconnected states and then adapt the data-structure-specific parts of search to explore it!
But what if we were interested not in any goal-directed problem but a specific one. Could we use information about the problem to create an algorithm that combines the direct-to-goal-nature of DFS with the good-answer-aspects of BFS? In other words, could problem-specific knowledge help us to identify and avoid paths that are unlikely to be a solution? As a concrete example, how might we adapt the goal-directed searches we’ve seen for the driving directions problem if we were given the as-the-crow-flies distance between each map location and the goal?
The as-the-crow-flies distance to the goal isn’t a set of driving directions (i.e., we’re not following the map!), but it does indicate which of two moves would bring us closer to the goal. Imagine using this distance to select the search algorithm’s next location from the frontier list. We’re using the distance to put the frontier list locations in a priority order. The higher the priority, the more likely that location will get us to the goal.
In general, prioritizing our possible search moves is the job of a heuristic function. The heuristic we use, of course, might be wrong. For example, we might have to drive in a direction away from the goal to find the road that will get us to it. Heuristics don’t guarantee that we’ll do better, but good ones, on average, find a near-optimal solution more quickly than our two uninformed solutions.
There are many heuristics in the domain of search. I asked you to imagine a common one (called greedy) that always takes from the frontier list the move with the best heuristic score. Another called A* search, which often yields more consistently good results, combines the cost of the path to the current point (e.g., the number of steps taken to get there) with the value of that point’s heuristic. Overall, there is a rich literature associated with search, and you are now prepared to dive into it to solve your own goal-directed search problems.