
Chapter 16: Catch Them Early#
A debugger helps us to understand and correct runtime errors, but to use it, you must have hit an error while running your script. If you’re lucky, the bug appears during one of your testing runs. If you’re unlucky, none of your tests exercise the execution path containing the bug, and you hit it while using your script to get some important work done. Even worse is when the bug remains hidden until one of your users hits it when they’re trying to get something done. No one likes to hear from angry users.
Writing test inputs that cover all the different execution paths in any nontrivial script is effectively impossible. But in Chapter 14, I mentioned that it’s possible to find some coding errors without running your script, which means you don’t need to construct a testing input. This approach to eliminating a whole variant of bugs from your programs involves understanding and employing static analysis tools.[1] While we won’t build such a tool in this chapter, we’ll learn how they work and why they’re powerful.
Learning Outcomes
Learn what it takes to find runtime bugs prior to running your scripts and why it is important to do so. You will understand the purpose of types, type checking, and how to use a type-checking tool. You’ll also learn how data abstraction makes static analyses difficult. After completing this chapter, you will be able to do the following:
Explain the basic operation of a static analysis tool that finds runtime errors in your scripts [design and CS concepts].
Discuss the similarities and differences between compiled and interpreted languages [CS concepts].
Describe the purpose of types, the difference between statically and dynamically typed languages, and the meaning of type errors [CS concepts and programming skills].
Illustrate the difference between the value and the type of an object [CS concepts and programming skills].
Detail the conditions under which it is important to perform static type checking and how it relates to dynamic type checking [CS concepts and programming skills].
Use Python type hints to aid a tool in static type checking [design and programming skills].
Divide-by-zero bugs. Think back to the time when you were learning to divide, and you might remember that you were told to never divide a number by zero. Division by zero is mathematically undefined because allowing it would lead to absurd results.[2] And yet, you can write the following Python script:
1### chap16/dbzero.py
2
3x = 42
4q = x / 0
5print(q)
While my IDE editor will flag many types of syntax errors by placing a red squiggly line under the offending syntax, it doesn’t indicate that there’s anything wrong in this script. However, when I ask the Python interpreter to run it, it raises a ZeroDivisionError exception on line 4. This is a runtime error, but why did I have to run the script to discover it?[3]
You might think that it would be straightforward to perform a string search over the script looking for instances of '/0', or something like it, with some flexibility in the whitespace between the characters. And with this thought, you’ve started to design a static analysis for finding divide-by-zero errors.
Division by the constant 0 is obvious, but how might you catch, without running it, the divide-by-zero error in the next code block?
1### chap16/dbzero1.py
2
3y = 0
4x = 42
5q = x / y
6print(q)
After a bit of reasoning, you probably figured out that the value of y on line 5 must be 0 because there’s only one assignment of y that reaches that line and it’s the one on line 3. Like our last example, we don’t need to run dbzero1.py to know that it has a divide-by-zero bug. Great! You just made your static analysis a bit smarter; it’s now capable of catching more variants of this runtime error.
Let’s consider one more example with a divide-by-zero bug, which I’ve listed in the next code block. It’s different from the previous two examples in that it doesn’t raise a ZeroDivisionError on every execution, but it will if the user responses with a zero.[4]
1### chap16/dbzero2.py
2
3y = int(input('Give me a number: '))
4x = 42
5q = x / y
6print(q)
In reasoning about this script, we know two facts when we think about the script’s execution reaching line 5:
The value of
xis the constant42.The value of
yis any integer.
Because the second fact allows for the possibility of y to be 0, our static analysis should report that there’s a divide-by-zero bug in this code. To eliminate this bug, the code should check the value of y and only allow the division to execute if the value is not zero.
Let’s summarize what we’ve learned from these three simple examples about the basic operation of a static analysis tool:
We can reason about a script’s execution by considering each statement’s execution beginning with the first statement in the program.
As we consider each statement, we interrogate the facts we know about the script’s current runtime environment and update these facts given what we know about the statement’s semantics.
Unlike the script’s actual execution, a fact about a variable like
ymight not be a single value but a set of possible values. Using sets, a static analysis tool can consider all possible executions at once, which is a very powerful approach. And despite having variables whose exact value we don’t know, we can still uncover runtime errors.
A silly coding error. Now that you’re warmed up, you’re ready to see if you can act like a static analysis tool and find a bug in a bigger script. The main function of the script emdash.py takes a paragraph of text and allows the user to indicate that they’d like to replace the commas around a parenthetical phrase[5] with em dashes.
Given the sentence:
In Chapter 16, we’ll learn that it is possible, using static analysis tools, to find some of your script’s coding errors without editing or running it.
The main function would, with direction from the user, turn it into:
In Chapter 16, we’ll learn that it is possible–using static analysis tools–to find some of your script’s coding errors without editing or running it.
You Try It
While I haven’t provided you with a lengthy description of how to run emdash.py or the script beyond its main function, you don’t need it to find the runtime bug in main. You need only to understand how Python operators and some commonly used methods work. Read through the script and see if you can identify the bug. You can assume that the call to get_phrase_index on line 51 returns a valid integer in the range 0 to len(phrases)-1. If you don’t immediately see the bug, don’t fret. Humans are not good at this sort of detailed work. And no cheating by running the script!
1### chap16/emdash.py
2"""Limiting assumption: This script works with paragraphs
3in which all sentences end with periods, and no period
4characters are used for any other purpose."""
5import sys
6
7# Terminal colors
8C_RESET = '\033[0m'
9C_RED = '\033[31m'
10C_BLUE = '\033[34m'
11
12def main():
13 # Check usage
14 if len(sys.argv) != 2:
15 sys.exit('Usage: python3 emdash.py paragraph.txt')
16
17 # Grab the paragraph and convert any newlines into spaces
18 with open(sys.argv[1]) as fin:
19 paragraph = fin.read()
20 paragraph = paragraph.replace('\n',' ')
21
22 # Print out instructions
23 print( \
24"""**INSTRUCTIONS**
25As you look at each sentence in this paragraph, tell me
26via a phrase index if you want to surround that phrase
27with em dashes rather than the existing commas.""")
28
29 # Iterate through each candidate sentence in text.
30 # A sentence is a candidate only if it has three
31 # or more phrases in it.
32 sentences = paragraph.split('.')
33 sentences = sentences[:-1] # last item isn't a sentence
34 for i, s in enumerate(sentences):
35 # Split the sentence into phrases
36 phrases = s.split(',')
37 if len(phrases) == 1 or len(phrases) == 2:
38 # Nothing to do
39 continue
40
41 print() # blank line in output
42
43 # Number and print the phrases
44 for j, p in enumerate(phrases):
45 if j != 0 and j != len(phrases) - 1:
46 print(f'{C_BLUE}{j+1}: {p}{C_RESET}')
47 else:
48 print(f'{j+1}: {p}')
49
50 # Grab a phrase index from the user, if any
51 a = get_phrase_index(phrases)
52 if a == 0:
53 continue # Leave the sentence alone
54
55 # Add back the comma on the unaffected phrases while
56 # building the sentence prefix and suffix.
57 s_prefix = ''
58 s_suffix = ''
59 for j in range(0, a):
60 if j != a - 1:
61 s_prefix += phrases[j] + ','
62 else:
63 s_prefix += phrases[j]
64 for j in range(a + 1, len(phrases)):
65 if j != len(phrases) - 1:
66 s_suffix += phrases[j] + ','
67 else:
68 s_suffix += phrases[j]
69
70 # Add the em dashes to the affected phrase and remove
71 # the leading spaces in it and the s_suffix.
72 new_s = s_prefix + '--' + phrases[a].split() + '--' + s_suffix.split()
73
74 # Put the edited sentence back into the sentences list
75 sentences[i] = new_s
76
77 # Add back the periods and print out the new paragraph
78 for i in range(len(sentences)):
79 sentences[i] += '.'
80 print('\nNew paragraph:')
81 print(''.join(sentences))
Why compile? If compiled languages are more complicated to run than interpreted languages, why would you ever use them? There are basically three reasons:
Historical reasons. The first computers had little memory and little compute power, and this meant that you couldn’t simultaneously run the compiler while running your program. In fact, in the earliest days of computing, you couldn’t fit the compiler in the computer with anything else.
Performance reasons. Interpretation is comparatively slow. It allows you to quickly change your script and run bits of it, as we do in the interactive Python interpreter, but you pay for the language translation that takes place at runtime with slower program executions. In a compiled language, you compile (i.e., translate) your program once. When you go to run it, you’re just handing a bunch of machine instructions written in binary to your computer, which directly executes them. All the overhead of language translation is paid in the development process, not while the user is running your program.
Full-program analysis reasons. This the goal of this chapter. If we want to find runtime bugs without running the program, a great time to run a static analysis is at compile time, before we ship the program to any users.
Finding type errors. We learned that compiled languages naturally have a place for static program analysis (i.e., during language translation), but in an interpreted language like Python, language translation is hidden in the eval phase of the Python interpreter’s REPL, which takes place during program execution. Are we back to inserting a new step in our problem-solving process?
Luckily, no. Most IDEs editors are extensible, which means that you can load and run static analyses while you edit. These act like the spell check and grammar hints that run constantly in modern word processing applications. In an IDE editor, syntax highlighting, pop-up help, and error and warning reporting (often indicated with squiggly underlining) are all types of static analyses. So let’s extend our IDE with a static analysis that will uncover the bug in emdash.py.
As an example of an extension, I loaded and used mypy[7] in the Microsoft Visual Studio Code IDE. Mypy is a static type checker for Python. In a moment, we’ll discuss what this means and why it helps find an important category of runtime bugs. First, however, let’s look at Figure 38, which illustrates what we can learn from mypy.
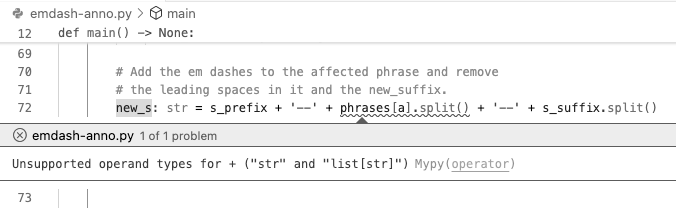
Fig. 38 Screenshot of an editor tab in Microsoft Visual Studio Code with the mypy Type Checker extension loaded (v2024.0.0). I’ve opened the error message associated with the squiggle on line 72.#
This tool placed a squiggle under a part of line 72. This line builds a new sentence in which we place em dashes around the parenthetical phrase named phrases[a]. As you can read in the comment on lines 70−71, the code should have removed the whitespace around this phrase and the text that came after it, which is what the specification for emdash.py said it should do. However, I mistakenly typed split() where I meant strip()—twice in fact. I had invoked the split method several times earlier in the script, and my fingers mindlessly typed it again rather than the similar-looking strip.
To squiggle or not. Knowing that I typed the wrong method name explains my error, but how did the mypy analysis know to place a squiggle on line 72? To figure out the answer to this question, we must understand what the mypy error message is telling us. It says that the + operator was attempting to act upon a string object and a list object holding string objects.[8] On line 72, the literal '--' is clearly of type str, but how did mypy know the type of the object produced by phrase[a].split()?
You might say that it’s obvious, but if you did, you assumed that this expression was calling str.split. This is true only if phrases[a] produces a string object, and while it is true in this script, it didn’t have to be true if we were reasoning about line 72 in isolation.
Python is a dynamically typed, object-oriented language. As we learned in Chapter 11, we can build objects of any structure we’d like using Python’s class syntax. So here’s another perfectly rational way to decide the type of the object between the two + operators on line 72: phrase names an object whose class defines the indexing operator (i.e., the [] operator, which you can define using the __getitem__ magic method).[9] The object returned by __getitem__ is one that defines a split method, and this method returns a string. This isn’t what mypy determined, but my point is that this alternate reasoning follows a perfectly valid set of assumptions given what we know about Python and what we see on line 72.
In summary, whether mypy decides to place a squiggle under phrases[a].split() depends entirely on whether its reasoning determines that the returned object is of type str or list[str]. And what makes such reasoning hard is not the object-oriented nature of the language but its dynamic typing.
Dynamic typing. In a dynamically typed language, we know a variable’s type only at runtime or, equivalently, the object’s type currently named by the variable. In Python, variables are simply names, and a name can refer to objects of different types at different points in a script. In other words, the name tells you nothing about the type of the object it names.
For example, consider the name my_variable in this code block:
1### chap16/dyntype.py
2
3choice = input('Pick an object type: ')
4my_variable = 'A' # default to str
5if choice == 'int':
6 my_variable = 65 # change to int
7elif choice == 'list':
8 my_variable = ['A', 65] # change to list
9print(my_variable, 'is of type', type(my_variable))
The type of the object named my_variable on line 9 is not definitively known until we run the script and learn the value of choice. Without this runtime information, the best a static analysis can determine is that it could be of type str, int, or list.
The process of statically determining the possible types of a variable in a dynamically typed language is quite like the process we performed to determine the possible values of the variable y in bdzero2.py. While previously we were interested in the possible values and here in the possible types, this difference didn’t change the structure of the analysis we performed. In both cases, we identified the statements that defined our variable of interest and then asked which of these definitions reached a particular program point. When multiple definitions reached a point, we combined the possibilities. In general, this combination work is more complicated than I’ve described, but understanding it as a set-union operation is fine for our work in this chapter.
Why types are interesting. To catch divide-by-zero errors, it was obvious that we wanted to know if a variable (or, in general, an expression) could be 0, but why is knowing the type of a variable also helpful in finding snippets of code that become runtime errors? Stated simply, it’s because an object’s type tells you the operations you can legally perform on or with the object.
Type checking, therefore, asks if there is ever a place in our script where we’re trying to manipulate an object (i.e., data) in a manner that is
explicitly forbidden (e.g., something equivalent to division by zero) or
not defined (e.g., we’ve never told the Python interpreter what it means to “add” a string literal to a list of strings).
Terminology
A type, or more specifically a data type, is an attribute of a piece of data, and this attribute tells the compiler or interpreter how it should interpret and how it can legally manipulate the datum.
Types versus values. Let’s make this attribute idea concrete. In Chapter 6, we learned that computers encode everything as numbers, which our computers store as bit patterns. In the following code block, we name the string 'A' and the integer 65, and then we ask the Python interpreter to show us the bit representations of these two objects. It responds that both values are encoded with the bit pattern 0b1000001. That’s interesting, since we know that the Python interpreter has treated them differently in our scripts. We can verify this by asking the interpreter whether these two objects are equal (i.e., the same). It responds False, which means that they’re not.
1### chap16/equal.py
2
3a_letter = 'A'
4an_int = 65
5
6# Show that their bit patterns match
7a_in_bits = bin(ord(a_letter))
8i_in_bits = bin(an_int)
9print(a_in_bits, i_in_bits)
10
11print(f'Does Python think these two objects are equal? {a_letter == an_int}')
Even though the bit patterns for the values of the objects named a_letter and an_int are exactly the same, the interpreter says that these objects are not equal. The reason that they’re not considered equal is because their types differ.
11### chap16/equal.py
12
13print(f'{a_letter} is of type {type(a_letter)}')
14print(f'{an_int} is of type {type(an_int)}')
The Python interpreter considers two objects equal when
the bit patterns of their values are identical, and
they are of the same type.
You’ve now learned that an object’s type is an important attribute of an object, and this attribute is different from the object’s value. An object’s type informs the interpreter (and us) what operations are legal to perform on or with this object’s value.
Dynamic type checking. So where are we? We’ve learned that types are important, but because of dynamic typing, we know that the name of an object doesn’t tell us anything about its type. Yet, the Python interpreter needs to know the types of the objects in a statement when it goes to evaluate that statement. Types tell the interpreter what operations are allowed and legal, and when you try to do something that isn’t, it raises a TypeError. Where does the interpreter get this necessary type information if not from the variable name?
The solution to this dilemma is that Python includes type information with every object it creates. We learned through equal.py that this information (i.e., this attribute) is kept separate from the value of each object. It is additional overhead (i.e., it causes an object to take up additional space in our computer’s memory), but because of this overhead, the interpreter can perform dynamic type checking (i.e., type checking at runtime). Now you understand how the interpreter is able to raise a TypeError when executing line 72 in emdash.py.
You Try It
Try running emdash.py by typing python3 emdash.py txts/debugging.txt at the shell prompt; this command assumes you have this chapter’s code distribution from the book’s GitHub repository. The contents of the file debugging.txt are a paragraph that contains the example that I mentioned earlier. The script identifies sentences in the paragraph that have multiple commas, and for each of these sentences, it will ask if you want to change a comma-surrounded phrase into an em-dash-surrounded one. Answer 0 if you don’t want to make any changes to a particular sentence. When you ask the script to perform the change on a comma-surrounded phrase, it will die with a TypeError on line 72, as expected.
Static type checking. And yet, we want to build static analyses that discover the TypeError on line 72 in emdash.py without having to run it. One way to provide a static analysis with the type information it needs is to attach the type information not to a program’s objects but to its variable names. This is, in fact, what happens in the C programming language. Here is equal.py rewritten as a C program:[10]
1/* chap16/equal.c */
2#include <stdio.h>
3
4int main(void) {
5 char a_string = 'A';
6 int an_int = 65;
7
8 printf("Does C think these two objects are equal? %d\n", a_string == an_int);
9
10 return 0;
11}
Notice that the assignments on lines 6 and 7 not only initialize the value of these two variables, but they also declare the type of each: a_string is declared to be of type char, which stands for character, and an_int is declared to be of type int. In other words, the type of every variable in a C program is known at compile time because every variable has its type explicitly declared.
The program equal2.c separates the variables’ declarations from their initializations to make this clearer. This helps illustrate the two things you should know about declarations in a language like C:
Declarations of a variable must come before any use of that variable.
Declarations have no runtime behavior; they are only information for the C compiler.
1/* chap16/equal2.c */
2#include <stdio.h>
3
4int main(void) {
5 /* declaration of two variables of different types */
6 char a_string;
7 int an_int;
8
9 /* initialization of the values of these variables */
10 a_string = 'A';
11 an_int = 65;
12
13 printf("Does C think these two objects are equal? %d\n", a_string == an_int);
14
15 return 0;
16}
You Try It
You can copy these two C programs into a Replit C project and run them for yourself (or any other environment with a C compiler installed). To compile equal.c in a Replit C project, you type make -s equal at the shell prompt, and then you run the resulting executable by typing ./equal at the shell prompt. You do the same for equal2.c. When these two programs answer the question about the equality of a_string and an_int, an answer of 0 means False and 1 means True.
Are you surprised at the answer? Here’s how to resolve this surprise:
Think about the bit patterns and the fact that that’s all that is compared in C at runtime. The type information is used at compile time and then discarded. The print-statement in these two programs really should say, “Does C think these two values are equal?”
Think about what this tells you about the two types,
charandint, if the C compiler’s static type check succeeded for the expressiona_string == an_int).[11]
Type hints. We are finally ready to understand how mypy operates and what we (as programmers) need to add into our scripts to enable it to do static type checking. As I mentioned earlier, dynamic typing is what makes static type checking hard. We need to know object types to do type checking, and that means we have to jettison Python’s dynamic-typing nature.
Perhaps you were a careful reader and noticed that the file open in Figure 38 is not emdash.py but emdash-anno.py. Furthermore, line 72 starts with:
new_s: str = ...
rather than
new_s = ...
This change is just different syntax for the variable declarations we saw in C (i.e., new_s: str declares that any objects named new_s are expected to be of type str). In Python, these are called a type hints. They’re hints because they’re not necessary for the functioning of the script (i.e., the Python interpreter still performs dynamic type checking, and you’re free to ignore the mypy error messages). You can think of these type hints as acting like comments, but unlike a typical comment, they’re meant not only for humans but also for static type checkers like mypy.
You Try It
Read the Python Enhancement Proposal (PEP) 484 to learn much more about type hints, and then look at emdash-anno.py to see how I used them to help mypy with static type checking.
No free lunch. Adding type hints does require us to be more explicit about what we’re doing when we code (i.e., we need to decide and state that a name will only ever hold objects of the declared type), but the benefit is that we can build tools that help us identify where in our code we violate those declarations, which may help us find many subtle bugs that would otherwise require numerous test inputs and extensive testing time. When the code we write doesn’t take advantage of dynamic typing—as is true with emdash.py, where none of its names ever hold more than one type of object—this is a small price to pay for the huge benefits of static type checking. However, when we do exploit the benefits of dynamic typing, type hints come with a real cost.
Do you remember the function my_replace from Chapter 3?
1### chap03/bookshelf1.py
2
3def my_replace(s, old, new):
4 """Returns a string replacing all instances of old with new."""
5 i = 0 # tracks where we are in the input string
6 j = len(old) # skip-ahead amount for index calculations
7 new_s = s[0:0] # the new string we're building
8
9 while i < len(s):
10 if s[i:i+j] == old:
11 new_s = new_s + new
12 i += j
13 else:
14 new_s = new_s + s[i:i+1]
15 i += 1
16
17 return new_s
18
19def main():
20 # Create a string object with a line from The Cat in the Hat
21 the_line = 'The Cat in the Hat!'
22 print(the_line)
23 the_line = my_replace(the_line, 'Hat', '\N{top hat}')
24 print(the_line)
25
26 # Create a representation of the objects on my shelf
27 stuffed_lion = '\N{lion face}'
28 kids_pic = 'kids.jpg'
29 textbook = 'cs32.scriv'
30 favorite_cd = 'BornToRun.mp3'
31 novel = 'CatInTheHat.txt'
32
33 # Create a sequence object that represents my shelf
34 shelf = [stuffed_lion, kids_pic, textbook, favorite_cd, novel]
35 print(shelf)
36
37 # Make it look like our textbook has been opened on my shelf
38 shelf = my_replace(shelf, [textbook], ['\N{open book}'])
39 print(shelf)
40
41if __name__ == '__main__':
42 main()
What type annotations should we use for the formal parameters of my_replace? We can’t use either str or list because this routine is supposed to work with any sequence that defines the length, slicing, and concatenation operators (i.e., the magic methods __len__, __getitem__, and __add__). Well, perhaps we might declare these parameters to be of type Sequence, whose definition you can import from the typing module, as I illustrate in bookshelf1-anno.py.[12] Unfortunately, this doesn’t work. Mypy will mark expressions like new_s + new as an error because not all sequence types in Python support concatenation. That was a design choice in the Python language, and it means that we’re left with no type that’s right for the data abstraction we built in my_replace. We must either eliminate this abstraction from our code base (and consider every error message from mypy a true error) or keep my_replace and decide that we’re going to ignore some of the “errors” flagged by mypy.
While things do get complicated, the main point is that tools exist that can help you to find the bugs that creep into your scripts, and static tools have the amazing power to look for errors in all the possible runs of your script without the need for test inputs. Unfortunately, while powerful and useful, all such tools do have their limitations. Take the time to learn the capabilities of each individual tool and be cognizant of their limitations (or how they put limitations on your coding). If you do, you’ll be able to more easily wring the bugs out of your scripts and more quickly solve the problems that matter to you.
Tip
As a Python programmer working in a dynamically typed language, you can benefit from a tool that performs static type checking. When writing in other programming languages, you’ll want to know how that language’s features can also be a vehicle for common runtime errors. For example, C is often described as a language that allows programmers to operate close to the machine’s hardware. It allows you to manipulate your computer’s memory in ways you cannot in Python, but it also requires you to manage your program’s dynamically allocated memory. C programmers, therefore, would want to invest in a tool that detects memory leaks and memory addressing errors. Python programmers wouldn’t ever use such a tool since memory management is handled completely by the language runtime.