
Chapter 18: Use Generative AI#
You’ve reached this book’s end, and we have one last problem to solve: How should you use the skills and knowledge you’ve gained in a world where generative artificial intelligence (GAI) can turn a short English description of a problem into working Python code? GAI is a computational tool that you can use to generate new content. It is (mostly) a predictive model that has been trained on a huge corpus of (typically) real-world data to be good at a particular task, like generating human-sounding text, Python code, images, or short videos.
Here’s an example using OpenAI’s ChatGPT (GPT-4):
Me: Write a python script that prints a text file so that each line starts with a line number.
ChatGPT: Certainly! Here’s a Python script that reads a text file and prints each line prefixed with its line number. I’ll include some comments in the script to explain each step.
1### chap18/num_lines.py -- Written by ChatGPT
2
3def print_numbered_lines(filename):
4 try:
5 # Open the file in read mode
6 with open(filename, 'r') as file:
7 # Read all lines in the file
8 lines = file.readlines()
9
10 # Loop through the lines, enumerate starts counting from 0 by default
11 for index, line in enumerate(lines, start=1):
12 # Print each line with its line number
13 # Strip is used to remove any extra newline characters before adding our own
14 print(f"{index}: {line.strip()}")
15
16 except FileNotFoundError:
17 # If the file is not found, inform the user
18 print("The file was not found. Please check the file path and try again.")
19
20# You can call the function with the path to the file you want to print
21# For example: print_numbered_lines("example.txt")
If you’re using this book in a course that has adopted my programming problem sets, you’ll recognize this prompt as part 1 of your first programming assignment. The code above is almost certainly not what you wrote then—it uses programming constructs and Python functions that we didn’t cover until later chapters. And it is not what you might write now—the try-except statement provides less information than the Python interpreter’s default error message. Nonetheless, you’ll see that this function works.
Are your new skills worthless? No!
As this book’s author, my emphatic no might not surprise you, but let me explain. At the start of Act I, you probably found this prompt to be a challenging task, but here at the end of Act III, you know that it isn’t. I ask my students to tackle this challenge because it helps them learn:
the basics of worklist processing, which is a widely applicable technique used in computational thinking and problem solving more generally;
to read and write several widely used statements in Python syntax; and
to recognize and fix flaws in a Python script.
You’ve learned these lessons, and you now can write this code as easily as you do basic math. And despite knowing how to do basic math, we don’t always choose to do it. Sometimes we rely on a calculator or a spreadsheet. While GAI tools don’t operate, as we’ll soon discuss, like calculators or spreadsheet programs, they’re useful when getting to an answer quickly is more important than doing the work ourselves. The same rule applies to GAI tools.
Act III has been all about tools, like GAI, that enable us to more quickly solve problems. It has covered two types of tools:
those that help us understand why a script failed (e.g., a debugger); and
tools that help us do less in Steps 5−7 of Chapter 1’s problem-solving process (e.g., machine learning libraries).
GAI tools assist in both ways. They don’t change the eight steps in our problem-solving process or eliminate the need to iterate when a script fails, whether it is one we wrote or a GAI-produced script. GAI tools can, however, pinpoint where in the problem-solving process we need to return and allow us to focus on the larger tasks involved in problem solving.
Learning Outcomes
Learn to use GAI, and large language models (LLMs) in particular, as tools for problem solving. You will discover that GAI tools don’t fundamentally change the problem-solving process we discussed in Chapter 1. You’ll gain an understanding how these tools operate and how they’re not like calculators and spreadsheets. You’ll learn how to use them so that you become a more productive problem-solver. After completing this chapter, you will be able to do the following:
Explain GAI in layman’s terms [CS concepts].
Use a simple framework to think precisely about how you’d like to employ a GAI tool [design].
Describe the general operation and training of a LLM [CS concepts].
Determine whether the problem-solving task you’ve assigned a LLM is within its capabilities, and when it is not, adjust your approach to get some benefit from the tool [design and programming skills].
Structure the prompts you give to a LLM through prompt engineering so that it’s more likely to successfully accomplish your requested task [programming skills].
Understand why “programming” in English (or any human language) is a double-edged sword [CS concepts].
Navigating the jagged frontier. While GAIs are tools that can augment your newly attained abilities, there are (at least) two gotchas. I’ll describe the first gotcha now, as further justification for my earlier emphatic no, and the second later, after we talk about how GAI, and LLMs in particular, work and are used in writing code.
The first is nicely illustrated by a 2023 study from Harvard Business School researchers.[1] They investigated how the productivity and work-product quality of knowledge workers changed when using a GAI tool. In their study, there were three sets of consultants:
those who were not allowed to use a GAI tool;
those who were allowed to use a GAI tool; and
those who were allowed to use a GAI tool and were told what makes a good prompt.
The study’s authors devised a set of tasks for these consultants to solve that were both within and beyond the capabilities of the GAI tool. The limit of the GAI’s abilities is what the researchers called its frontier. Like any person’s knowledge and skills, this frontier is jagged (see Figure 40), meaning that given a large number of tasks with the same perceived difficulty, the GAI tool will complete some of these tasks better than others. Or stated another way, for a task within the frontier, the GAI tool’s responses will be largely correct and helpful. But for a task outside its frontier, the GAI tool’s responses will be largely incorrect, although the flaws in its responses may not be immediately obvious.
Fig. 40 An illustration of the jagged frontier of any GAI tool’s capabilities. Some tasks, like A, are outside the GAI’s knowledge base, while others, like B, are inside it.#
This study’s findings tell an important story about how we should use GAI tools in our own work. On tasks within the frontier (i.e., where the GAI tool worked well), the authors observed the following:
Consultants using a GAI tool were “significantly more productive (they completed 12.2% more tasks on average, and completed tasks 25.1% more quickly), and produced significantly higher quality results (more than 40% higher quality compared to a control group).” (emphasis added)
Plus, those individuals with below-average skills benefited more from using a GAI tool (a 43% boost versus 17%). (emphasis added)
Perhaps unsurprising, when a tool is appropriate for the job at hand, you work faster and better. More surprising is the finding that, when individuals are less skilled, a GAI tool helps them even more. It is not often that a tool levels the playing field, helping novices more than power users.
Yet, on tasks outside the frontier (i.e., where the GAI tool is often wrong), the authors reported the following:
Consultants using a GAI tool were “19 percentage points less likely to produce correct solutions compared to those without AI.” (emphasis added)
Plus, those who were instructed on ways to write better prompts produced worse results. (emphasis added)
Clearly, understanding a tool’s frontier matters.
Tip
As a user of GAI tools, you need to know on what tasks a tool works well and not be lulled into blindly accepting what it produces. The companies producing GAI tools, for competitive reasons, won’t often tell you where this frontier is. Furthermore, as this third act has emphasized, it is not sufficient to learn how to use a tool. You must also understand its limitations.
While the capabilities of GAI tools will continue to improve, there will always be a frontier. With a general understanding of how GAI tools work and a little bit of critical thinking, you can discover a tool’s frontier. In the rest of this chapter, I’ll demonstrate this for the task of problem solving with computation using OpenAI’s GPT-4. By focusing your interactions with a GAI tool on areas where you need help and it is capable, you’ll be able to supercharge your newly acquired problem-solving skills.
My use of GAI. I just made a claim that isn’t too different from what you would hear from any company that is building or employing GAI. This technology is powerful, and it is going to change the way we work. But it is still early days, and only time will tell how things will change. We can, however, accelerate this discovery process by explaining to each other how we have used GAI in our own work.
For me, this begins with a disclosure that I’m using a GAI tool.
How I Used GAI
I acknowledge the use of OpenAI’s ChatGPT (GPT-4) in the development of this chapter’s content. The chapter’s organization and main points are entirely mine, and except where indicated, the text and code examples are mine.
For example, I asked GPT-4 to briefly describe GAI for students in a computational thinking class, and the last sentence in its response, which I’ve emphasized below, is something I decided to highlight more prominently in writing this chapter than I had in outlining it.
Me: What is generative artificial intelligence?
ChatGPT: Generative Artificial Intelligence is a type of AI that focuses on creating new content. It’s like an AI artist that can independently create something new rather than simply analyzing and understanding existing content. Examples of generative AI include AI systems that can generate music, images, or text. In a computational thinking context, the concept of generative systems helps us understand how complex output can emerge from simple rules and structures.
This example illustrates one of the ways I think about using a GAI tool. The full framework involves asking the following three questions:
Do I want to delegate some of my work to the GAI tool? I answer yes when I want the outcome (e.g., a summary of a long essay, or finding and understanding a bug in my Python program), but the process of producing the outcome is not something I need to do.
Do I want the GAI tool to nudge along my creativity? I answer yes when I think that the GAI tool might help me expand on my initial ideas or generate a broader set of examples. This is what I did above. I want the outcome (e.g., a chapter that appeals to a wide range of readers), and it’s important that I’m intimately involved in the process of generating it.
Do I want the GAI tool to check and suggest corrections for the details in my work? I answer yes when my work is near completion and I’m looking for feedback, improvements, or corrections. Machines, which don’t get distracted or tired, are often better than humans in carefully checking the details.
We’ll use this framework throughout this chapter, and I hope you find it useful in your own interactions with different GAI tools.
Large Language Models (LLMs). To navigate the jagged frontier of a GAI tool, it helps to have a basic understanding of how they work. I’ll briefly describe the functioning of LLMs, which are the foundation for today’s AI coding assistants. GPT-4 is a LLM and one of the multiple models powering the chat interface that is ChatGPT. While I’ll focus on GPT-4, what you’ll learn is equally applicable to the LLMs available from other companies.
LLMs are essentially functions that map a text input to a text output.
input_text = 'What is generative artificial intelligence?'
output_text = GPT4(input_text)
More specifically, LLMs attempt to create a reasonable continuation of the text input. To understand what this means, think of a conversation between two people. You’d expect that the second speaker’s remarks (i.e., ChatGPT’s response) will be related to what the first person (i.e., you) just said (i.e., your prompt to ChatGPT). In other words, output_text is ChatGPT’s reasonable conversational response to your prompt input_text.
When speaking with another human being, our reasonable continuations rely on:
shared understandings from our common experiences;
the human capacity to put ourselves in another’s shoes (i.e., empathy); and
societal norms.
Machines have none of these things, but they can generate what some people might likely say in a particular context based on an analysis of:
the text on the billions of web sites across the Internet;
the content in the millions of digitized books; and
the transcripts of many online videos.
LLMs are a classic use of online and offline work, where the offline work is the kind that we covered in Chapter 17:
Offline: create a huge data set of human writings.
Offline: train and validate a prediction model using this data set.
Offline: tweak the model with human feedback, which you can think of as socializing the model’s responses with help from humans.
Online: grab a human’s prompt and use the model to repeatedly predict the words that would likely come next, with some idea of when it’s good to stop speaking (i.e., end the model’s response).
The operation of LLMs. Let’s begin by understanding the computational work being done in the final online step. I’ll lean on the work of Stephen Wolfram, who published in 2023 an excellent introduction to LLMs based on some experiments he performed with an early version of OpenAI’s GPT system (GPT-2).[2] As this work explains, what looks to us through the ChatGPT interface as a prompt and a lengthy response is actually multiple calls to the GPT model.
Let’s take these calls one at a time. Wolfram’s opening example, which I’ll describe, begins with the prompt string "The best thing about AI is its ability to" and the GPT model responds with a token (i.e., a word, part of a word, or a punctuation mark) that is a reasonable continuation of it.
the_next_token = GPT2("The best thing about AI is its ability to")
From its training, the model has seen that the word “learn” comes next in contexts like this, but this word is not the only reasonable continuation. As Wolfram 2023 reports, GPT-2 also generates “predict,” “make,” “understand,” “do,” and many other words as possible continuations. In fact, GPT-2 computes with each generated word what we can think of as a probability; the higher the probability, the more likely it is that the word is a reasonable continuation based on its training.
To return one of these generated words, GPT-2 must make a choice, as illustrated in Figure 41. Should it select “learn,” which is the choice with the highest computed probability? Or should it select one of the other highly ranked words?

Fig. 41 The top five most likely words that GPT-2 predicts will reasonably continue the prompt “The best thing about AI is its ability to” (Source: Stephen Wolfram, “What is ChatGPT Doing … and Why Does It Work?” February 14, 2023).#
Through experience, LLM developers have discovered that models that always return the highest-ranked next word produce responses that sound flat and repetitious to humans. Models with more natural-sounding responses vary the choice of words from those most highly ranked.[3]
But let’s continue with Wolfram’s example in which the model chose “learn” from this list. The conversation’s context is now “The best thing about AI is its ability to learn” and the next step is to call GPT-2 with this string. The model provides the next word (e.g., the word “from”), and we again update the context. We have now defined the body of a loop: the model chooses a word that is a reasonable continuation of its current context and then uses its choice to update the context.
The next obvious question is: What is this loop’s exit condition? As we’ve learned, loops need at least one. A straightforward answer to this question is to use a special END token. The model generates a probability for END on each call, and when this token is selected, the model has determined that it is reasonable to end the loop and return the response.
Complexity from simplicity. Earlier, when I asked ChatGPT to explain GAI, it responded that these systems help us to “understand how complex output can emerge from simple rules and structures.” This statement refers to the building blocks and basic layout of a LLM (and many other AI models like image recognizers), which I’ll now briefly describe. My point is not to have you comprehend all the details, but to realize that a GAI model isn’t constructed and programmed like a calculator or spreadsheet application. Structurally, GAI models are neural networks, which were inspired by the biological structure of the human brain (i.e., the brain’s networks of neurons).
Neural networks were first proposed in the 1940s, and today’s computational neurons are largely unchanged since then. What’s changed is the computing speed of these neurons, the number of them we can interconnect and train, and the size of the training data sets. Everything has become orders of magnitude faster and bigger.
Figure 42 is a typical and idealized illustration of a neural network. The computational neurons are organized into layers. Inputs to the model are fed to the first layer of neurons, which compute with these inputs and whose outputs are fed to the next layer of neurons. This feed-forward organization continues until the last layer outputs the model’s result.
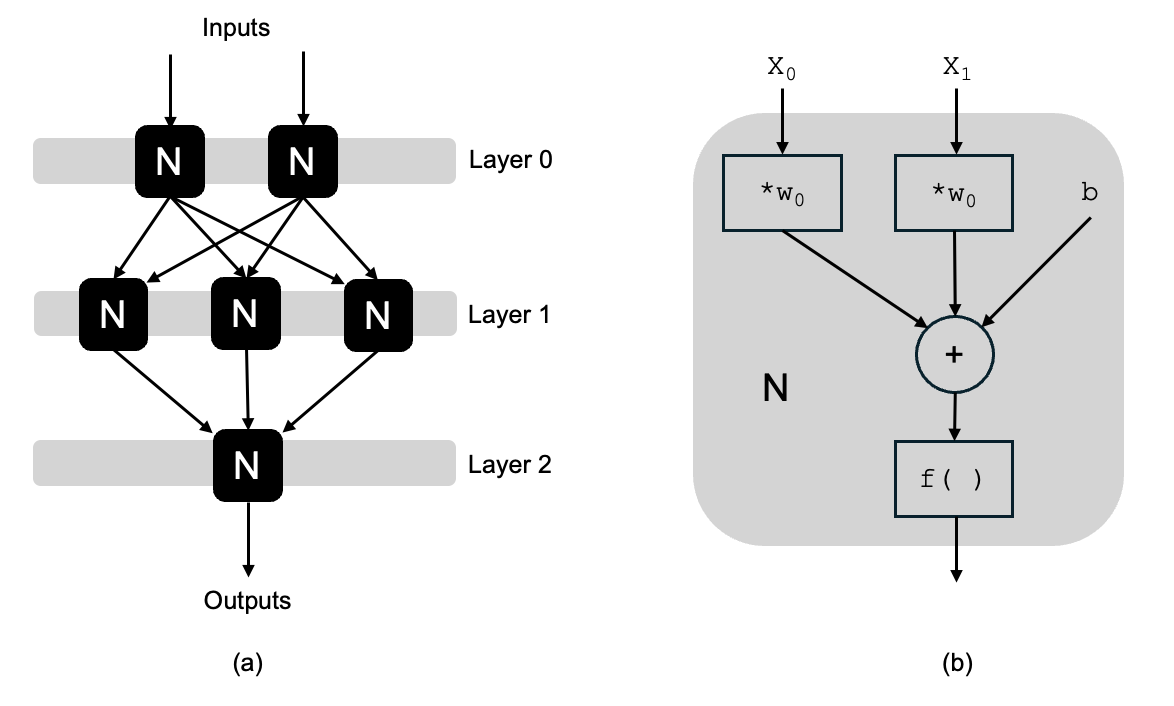
Fig. 42 (a) The rough structure of a neural network. It is a directed graph where values flow along the edges (arrows) from the network inputs and through each layer of computational neurons (rounded squares). (b) Each neuron performs a simple numerical computation..#
Inside each individual neuron, the work that is done can be expressed as follows:
sum the weighted values on the \(n\) incoming edges: \(\sum_{i=1}^{n} (w_i * x_i)\) , where \(w\) is a weight and \(x\) is an incoming value;
add a constant \(b\);
invoke a thresholding or activation function \(f\) on the previous result.
Each computational neuron in a model’s neural network typically has its own set of weights for the incoming edges and its own constant \(b\). These are the parameters that you hear mentioned when a company quantifies the complexity of its model. They are also what are set through training, as we’ll discuss next.
The thresholding or activation function is typically the same across all computational neurons in a layer. More interesting is its purpose, which is to allow for nonlinear behavior out of a layer.
While a neuron’s computation may not sound simple to you, it is much simpler than all but the most trivial of the programs we’ve been writing throughout this book. Perhaps someday someone will figure out how human-sounding responses come from such simple structures, but as of today, we can’t explain it. Furthermore, engineering a useful neural network continues to be more of an art than a science.
Training a neural network. Training a neural network (i.e., setting its parameters) relies on a combination of straightforward calculus and engineering art. The calculus is not important to achieve the goals of this chapter. By engineering art, I mean that the success of today’s LLMs depends significantly on many seemingly arbitrary engineering decisions. It also takes a lot of time, money, and training data. We got an inkling of this challenge in the last chapter.
But, at a high level, we can train a LLM using supervised learning. We take sentences from our corpus of real-world examples and mask out the ends of them. We then measure the difference between the model’s answer and the actual sentence endings. Using this difference, we nudge the model toward better responses by changing its parameters. LLM developers continue to do this until they’re happy with the model’s responses. Again, this should remind you of the machine learning (ML) work we discussed in the Chapter 17, although measuring the difference between words is not as simple as the difference between home prices.
To make this concrete, consider the following start to a sentence: “The sky is _____”. From our data set of real-world sentences, we know that “blue,” “stormy,” “falling,” “endless,” and “empty” are all reasonable continuations, while words like “able” and “tape” are not. Which word from the first list should the model prioritize? That would depend upon the context of the conversation before this sentence.
My last point hints at something that LLMs are not doing and that you should understand. They are not a really big hash table that hashes the input prompt to access a stored list of reasonable words. If you think about it for a moment (or do the math that Wolfram 2023 describes), you’ll quickly realize that there are too many prefix possibilities to even conceive of building such a table. This also means that the training set cannot contain every possible user prompt, since it is of a large but limited size.
But this is all OK. LLMs are exactly what the M in the acronym stands for: a model. The word probabilities generated by a model like GPT-2 and GPT-4 are just estimates informed by its training. The word it generates needs to fit the patterns seen in the training set, not any particular example. If it helps, recall that the sales-price predictor in the Chapter 17 used attributes of a previously unseen house to predict its sales price. This home didn’t have to be in the training set.
Terminology
The acronym GPT in the ChatGPT application name and other GPT-x models stands for “generative pre-trained transformer.” You now know how to explain the first two terms. Its last term, transformer, refers to a specific architecture of neural networks that focuses the model’s attention on specific parts of the input prompt. It’s kind of like choosing the right set of attributes on which to focus our sales-price predictor.
Two pieces to problem solving with GAI. It’s time to get back to problem solving. At the start of this chapter, I demonstrated how a context specified through a prompt and a model trained on all the Python examples in GitHub and elsewhere online could, through reasonable continuations, create a working Python script for the problem described in the prompt. Will this always work? Well, it depends on:
how competent we are at providing a “good” prompt; and
whether the problem we want solved is within or beyond the model’s frontier.
We haven’t spoken about what makes a good prompt, but we will. On the other hand, the preceding discussion provided some foundational knowledge with which we can think critically about a model’s response to a prompt. Our goal in this thinking is to decide whether the task we’ve given a GAI tool is within or beyond its frontier. And when it is beyond its capabilities, I’ll show you how you can nonetheless benefit by combining the tool with the skills and knowledge in this book.
An easy request? As we’ve done in every other chapter, let’s proceed with a problem-to-be-solved. Here’s the setup: When I teach my introductory computer science course using this book, I have the students practice their knowledge of goal-directed search (Chapter 11) by writing a program that plays the parlor game Six Degrees of Kevin Bacon.[4] In this game, players challenge each other to connect two actors by:
describing a chain of actors, bracketed by the two given actors; and
for each pair of consecutive actors in the chain, naming a movie in which they both costarred.
For example, Kevin Bacon and Marlon Brando are connected through Jack Nicholson:
Bacon and Nicholson starred together in A Few Good Men.
Nicholson and Brando starred together in The Missouri Breaks.
The chain Bacon-Nicholson-Brando is said to have a measure of two degrees-of-separation—that is, it took two steps (or movies) to go from Bacon to Brando.
My students test their programs on a small slice of the Internet Movie Database (IMDb) data sets,[5] and when they think their code works, I ask them to try it on a much larger slice. My pedagogical goal is to demonstrate that your code may functionally work, but large data sets can stress it in ways that small data sets don’t (e.g., quickly show you where your code is inefficiently implemented).
The chain I showed with Bacon, Nicholson, and Brando is found through a breadth-first search on the large IMDb data set, and when running a depth-first search, their programs often produce answers with much larger degrees of separation. The graph of actors and movies is highly interconnected, and there exist many chains from Bacon to Brando. Without fail, some students will come to me and ask if their script’s depth-first search output, like the following that reports 66 degrees of separation, is correct. I look at them and say, “I don’t know. How would you check this output?”
Name: Which 'kevin bacon'?
ID: 9323132, Name: Kevin Bacon, Birth:
ID: 102, Name: Kevin Bacon, Birth: 1958
Intended Person ID: Name: Running a dfs search
66 degrees of separation.
1: Kevin Bacon and John Goodman starred in Death Sentence
2: John Goodman and Carey Mulligan starred in Inside Llewyn Davis
3: Carey Mulligan and Joel Edgerton starred in The Great Gatsby
4: Joel Edgerton and Hanna Mangan Lawrence starred in Acolytes
5: Hanna Mangan Lawrence and Aden Young starred in Dark Frontier
6: Aden Young and Marshall Napier starred in Shotgun Wedding
7: Marshall Napier and Bruce Lyons starred in The Navigator: A Medieval Odyssey
...
64: Mimi Denissi and Louis-Do de Lencquesaing starred in Blind Sun
65: Louis-Do de Lencquesaing and Marthe Keller starred in The Holy Family
66: Marthe Keller and Marlon Brando starred in The Formula
You Try It
Take a moment to understand this captured output, including its first four lines. I captured this output by redirecting the solution script’s standard output, as we discussed in Chapter 13. Because I only captured the script’s standard output, you don’t see my answers to the script’s input prompts, which traveled over the script’s standard input. At the first occurrence of Name:, the script asked for the first actor’s name, to which I responded with the name “kevin bacon.” The next question comes on the same output line because the newline character was in my input response. The output Which 'kevin bacon'? and the two ID lines occurred because there are two actors with this name in the IMDb data set, and the script wanted to know which one I meant. To the Intended Person ID: prompt, I responded with the number 102. The script then asked for the second actor’s name, and I typed the name “Marlon Brando.” With the data it needed, the script then began running a depth-first search (DFS). It reported finding a chain with 66 degrees of separation and printed it.
The copy of the output above doesn’t show all 66 lines in the chain, but hopefully you see the pattern. Each line is of the form “ACTOR1 and ACTOR2 starred in MOVIE” where the uppercase nouns are placeholders for actor names and movie titles. A properly functioning goal-directed search, as we discussed in Chapter 11, shouldn’t visit the same node (i.e., actor) more than once. This means that no actor should appear in the last 66 lines more than twice.
To check this, we have three options:
Check the list by hand counting the occurrences of each name.
Write a Python script to analyze this output as we would have done by hand.
Ask ChatGPT to do it for us.
The students are asking me because Option 1 is undesirable and error prone. Using my earlier framework, this problem-to-be-solved is a classic example of work everyone wants to delegate.
Write the script ourselves. Option 2 isn’t hard. We learned in Chapter 13 how to use regular expressions (REs) to pull out pieces of text from blurbs that follow a pattern, and it’s straightforward to use a Python dictionary to keep track of how many times we saw each name. After about an hour’s worth of work, including some googling of syntax and test runs to verify that my code functioned properly, I had a function check that solved this problem.
1### chap18/check_chain.py
2import re
3import sys
4
5# Terminal colors
6reset = '\033[0m'
7red = '\033[31m'
8blue = '\033[34m'
9
10def increment(d, key):
11 '''Increment the count for key `key` in dictionary `d`'''
12 if key in d:
13 if d[key] > 1:
14 print(f'Actor "{red}{key}{reset}" occurs too often')
15 sys.exit()
16 else:
17 d[key] += 1
18 else:
19 d[key] = 1
20
21def check(lines):
22 '''Make sure no actor occurs more than twice'''
23
24 # Dictionary where we keep a count of instances of each actor
25 count = {}
26
27 # Compile the fancy RE
28 the_re = r'\d+:\s+([ \-\'\w]+) and ([ \-\'\w]+) starred in (.*)$'
29 p = re.compile(the_re)
30
31 # Process each line grabbing the actors and the movie
32 for line in lines:
33 # Skip any blank lines
34 if line == '':
35 continue
36
37 # Run match on current line
38 m = p.match(line)
39
40 # Error checking
41 if m == None:
42 # I missed a case for the RE
43 assert False, f'Died on line: {line}'
44
45 # Pull out the parts
46 actor1 = m.group(1)
47 actor2 = m.group(2)
48 movie = m.group(3) # currently unused
49
50 # Put the actors in the dictionary
51 increment(count, actor1)
52 increment(count, actor2)
53
54 print(f'{blue}No repeated actors!{reset}')
In designing the function check, I decided that its formal parameter lines would expect only the lines that fit the pattern ACTOR1 and ACTOR2 starred in MOVIE. As such, I do a bit of preprocessing on the captured output before invoking check.
58### chap18/check_chain.py
59
60with open(input('Filename? ')) as f:
61 lines = f.readlines()
62
63 # Figure out how many initial lines to remove
64 i = 0
65 while 'degrees of separation' not in lines[i]:
66 i += 1
67
68 check(lines[i+1:])
You Try It
Run python3 check_chain.py test_wo_error.txt, which feeds our script with the output my students asked about. The script verifies that the output is correct (i.e., no names are repeated more than twice). You should also try the two text files named with the pattern test_w_error*.txt, which check_chain.py will flag as problematic.
Ask ChatGPT. While Option 2 isn’t hard, perhaps we could save the hour that it took me to produce check_chain.py and instead ask ChatGPT to check the output directly. ChatGPT allows you to upload a file with your prompt. So I uploaded test_wo_errors.txt and asked: “Are any of the names in the attached text repeated more than twice?” Here’s how ChatGPT replied:
ChatGPT: Upon analyzing the text, I found that the name “Kevin Bacon” appears twice in the document. There are no other names repeated more than twice in the text provided.
It’s true that “Kevin Bacon” appears more than twice because I forgot to ask ChatGPT to ignore the first several lines, as I did when running my check function.
Tip
You still need to think when you ask a GAI tool to do your work.
But ChatGPT’s first sentence in the response doesn’t really make much sense. I asked if any names appeared more than twice, and while it correctly identified “Kevin Bacon” as appearing too many times, it wrote that this name “appears twice in the document” (emphasis added). This caused me to ask ChatGPT to “please explain how you came to that answer,” and it replied:
ChatGPT: To determine if any names were repeated more than twice in the text file, I performed a search in the file’s contents for all occurrences of names. This search was conducted using the uploaded file’s content where names were explicitly identified, and the data was systematically checked for repetitions.
In the file, “Kevin Bacon” is mentioned twice explicitly in different contexts (as part of an identification process and in a detailed listing related to “degrees of separation”). I reviewed the list of other names that appear throughout the text, each linked to various interactions and connections, but none were mentioned more than twice.
Based on this analysis, I concluded that “Kevin Bacon” is the only name that appears twice, and no names exceed this number of mentions in the text.
This sounds good, albeit it’s quite a high-level description. I’m thinking now, and so I decided to see if ChatGPT could really find a name repeated more than twice when that name occurred only in the part of the file that mattered (i.e., the chain of actor names). I copied the original output, duplicated the last line, and inserted Louis-Do de Lencquesaing between Marthe Keller and Marlon Brando in the chain of actors. Notice that Louis-Do de Lencquesaing also occurs at chain links 64 and 65. Here’s the end of this new test file, which I called test_w_error2.txt.
Name: Which 'kevin bacon'?
ID: 9323132, Name: Kevin Bacon, Birth:
ID: 102, Name: Kevin Bacon, Birth: 1958
Intended Person ID: Name: Running a dfs search
66 degrees of separation.
1: Kevin Bacon and John Goodman starred in Death Sentence
...
64: Mimi Denissi and Louis-Do de Lencquesaing starred in Blind Sun
65: Louis-Do de Lencquesaing and Marthe Keller starred in The Holy Family
66: Marthe Keller and Louis-Do de Lencquesaing starred in I Made This Up
66: Louis-Do de Lencquesaing and Marlon Brando starred in The Formula
The following is my prompt and ChatGPT’s answer:
Me: Please tell me which names are mentioned more than twice in the attached text file. (I attached
test_w_error2.txt.)ChatGPT: After reviewing the attached text file and analyzing the content for repeated names, here are the findings:
Kevin Bacon - Mentioned twice.
Louis-Do de Lencquesaing- Mentioned three times.
John Goodman, Carey Mulligan, Joel Edgerton, Heidi Armbruster, and Marthe Keller - Each mentioned twice.
Louis-Do de Lencquesaing is the only name that appears more than twice in the document. This conclusion was reached by methodically going through each line of the text and counting the occurrences of each name, focusing especially on those that appear multiple times.
ChatGPT correctly finds that Louis-Do de Lencquesaing is mentioned too many times, but it still struggles with counting. And it strangely tells me about a few but not all the other actors mentioned twice.
Tip
ChatGPT works quickly, but you’ll spend additional time debugging its work.
At this point, I haven’t found a prompt that causes ChatGPT to tell me exactly what I want to know and in a manner that makes me confident of its work. The reason I’m not getting a good result from ChatGPT could be that: (1) my skills in prompting need improvement; or (2) this task is beyond the model’s frontier. These are exactly the two challenges that I mentioned earlier in problem solving with GAI. Let’s deal with them one at a time.
Is this task within the frontier? There’s no easy answer to this question because no one can yet explain exactly how a GAI tool can solve the kind of task we just gave GPT-4. We can build these models, but we cannot explain how a prompt produces a specific response. There are many smart researchers working on this challenge of explainability in GAI systems.
Until this challenge is solved, I use a heuristic. We talked about heuristics in Chapter 11. They are approximate methods that largely but not perfectly answer a hard question. A good heuristic is practical to compute and not badly wrong. So what is a heuristic method for deciding whether your task is within your GAI tool’s frontier?
My approach flips the challenge of explainability on its head. Instead of a human trying to explain to another human how a GAI tool came to the particular response, I request the GAI tool to explain how it came to that response. If it provides me with an understandable explanation, I’ll believe that the task is within its frontier. When it doesn’t convince me, one of the following three things is true:
The task is outside the model’s frontier, and it can’t provide a convincing explanation because it didn’t actually solve the task (e.g., it hallucinated a solution).
The task is within the model’s frontier, but explaining to me what it did is not within its frontier.
The task and the ability to explain the solution are within the model’s frontier, but I’m not smart enough to understand the explanation.
I can’t tell the difference between these three cases, but I don’t have to. If I assume the GAI tool can’t solve the task whenever it can’t convince me, I won’t use an incorrect solution. This conservative approach also has the nice property that it will improve as the capabilities of GAI tools improve (and as I become smarter).
You’ve previously seen me using this approach with ChatGPT. Assuming the prompts I used were clear and unambiguous (an issue we’ll explore later), I can conclude through our prior work with GPT-4 that it isn’t fully capable of robustly solving our problem-to-be-solved.
The expanding frontier. As an example of GAI’s expanding frontier, let’s look at another example from Wolfram 2023. It describes the training of a GPT-2-like model for recognizing and producing sequences of balanced parentheses, as one sees in mathematical and programming language expressions. The GPT-2 model works well for short sequences of opening parentheses (e.g., the model correctly responds that it should follow ((( with )))), but the highest-probability completion for long sequences of opening parentheses doesn’t always produce a response that’s balanced. Wolfram 2023 theorizes that this model can reliably solve only things that humans can solve at a glance. When humans need to start counting and matching parentheses, the model should too, and GPT-2 doesn’t.
I’m not limited to GPT-2, and so I asked GPT-4 to “generate a balanced set of parentheses” and gave it several examples (i.e., what’s called few-shot prompting, as we’ll discuss later). GPT-4 correctly solved the long sequences that GPT-2 couldn’t. When I asked GPT-4 to explain its work, it showed me a piece of Python code, which I have put in balance_parentheses.py in the book’s GitHub repository. In other words, unlike GPT-2, GPT-4 was “smart enough” to realize it should build an algorithmic solution and use it. More tasks were inside its frontier than GPT-2.
Unfortunately, not all tasks are inside GPT-4’s frontier. When I continued to prompt it and provided the prefix ()()), which can’t be made balanced by adding more parentheses, it responded: “The input ()()) is already balanced, so the output remains ()()).” The reason it gave for the answer was the same balance_parentheses.py code, which doesn’t check for the condition in my example.
How to problem-solve with a LLM. Now that we’ve conservatively decided the complete problem-to-be-solved from my introductory computer science class is not within GPT-4’s frontier, how should we proceed to get benefits from using it? Simple. We decompose this problem into its tasks as if we were going to solve it ourselves, and then we ask for GPT-4’s help in solving the most difficult of these smaller tasks.
# Grab the filename and read in its lines
# Strip off the lines up to and including 'degrees of separation'
# Grab the names out of each line and insert them in a dictionary
# If a name occurs more than twice, we have a problem
The hardest task in this decomposition is grabbing the names from each line. So let’s ask ChatGPT to help with that:
Me: Please write me a Python function that removes the names from a line like “Carey Mulligan and Joel Edgerton starred in The Great Gatsby”
ChatGPT: To remove the names from a sentence like “Carey Mulligan and Joel Edgerton starred in The Great Gatsby,” we can create a Python function that identifies patterns resembling names (typically capitalized words) and removes them. This approach assumes that names are the capitalized words before the verb “starred” in the sentence.
Here’s a Python function that employs regular expressions to identify and remove these patterns:
1### chap18/remove_names.py -- Written by ChatGPT
2import re
3
4def remove_names_from_line(line):
5 # Pattern to find capitalized words followed by 'and' or 'starred'
6 # This regex assumes that names are always before 'starred' and start with capital letters
7 pattern = r'\b[A-Z][a-z]*\s(?:and\s)?[A-Z][a-z]*\s(starred)'
8
9 # Replace the names and 'and' if it appears with 'starred'
10 # This keeps the structure of the sentence but removes the names
11 clean_line = re.sub(pattern, r'\1', line)
12
13 return clean_line
14
15# Example usage
16line = "Carey Mulligan and Joel Edgerton starred in The Great Gatsby"
17print(remove_names_from_line(line))
When you run this script, it prints: Carey Mulligan and starred in The Great Gatsby. ChatGPT took me literally and removed the second actor’s name from the line. This is not the interpretation of my prompt that I wanted. English is ambiguous!
Tip
While “programming” a GAI in English (or any human language) might make problem solving with computation accessible to more people across the world, there’s a reason why programming languages attempt to have well-defined semantics.
Still, ChatGPT gave me a starting point for a solution and an explanation (not shown) of what went into the RE pattern it used. I’ll likely solve my problem faster with this assistance.
Writing good prompts. Now that you’ve seen some prompts, it’s finally time to discuss what makes a good one. This topic is also called prompt engineering. I begin with three often-recommended ways to prompt a LLM. While effective, they’re also very formulaic. To provide you with more freedom to express your prompts and still have them be good, I’ll then briefly discuss what I believe makes a good prompt.
The following are three popular prompt forms frequently cited by those with expertise in prompt engineering:
Instruction: This form begins with a command to the model that instructs it to do a particular task, then you follow the command with your supporting data or context. For example, your prompt might begin with the statement: “Summarize the following text in a paragraph.” You’d follow this statement with the text to summarize.
Completion: This form begins with the context you want the model to absorb and ends with an incomplete statement that the model naturally tries to complete. Continuing with the example that I used in the instruction form, you could start your prompt with the text that you’d like summarized and then end with an incomplete sentence (e.g., “Briefly, this text discusses”).
Demonstration: This form has you show the model what you want it to do through one or more examples and end with the question you want answered. It is reminiscent of supervised learning, and it is frequently called few-shot learning.
As an example of a completion prompt, let’s continue to try to get ChatGPT to grab the actor names from a line of the form: ACTOR1 and ACTOR2 starred in MOVIE.
Me:
Input: Carey Mulligan and Joel Edgerton starred in The Great Gatsby
Output: Carey Mulligan; Joel Edgerton
Input: Joel Edgerton and Hanna Mangan Lawrence starred in Acolytes
Output: Joel Edgerton; Hanna Mangan Lawrence
Input: Jane Tsentas and Cleo O’Hara starred in Evil Come Evil Go
Output: Jane Tsentas; Cleo O’Hara
Input: Aden Young and Marshall Napier starred in Shotgun Wedding
Output:
ChatGPT: Aden Young; Marshall Napier
It worked, and to have ChatGPT generate code I could use, I can follow this demonstration prompt with an instruction prompt: “Please write me a Python function that does this work.” When I did this, ChatGPT produced the following function:
1### chap18/extract_actors.py -- Written by ChatGPT
2import re
3
4def extract_actors(input_string):
5 # Regular expression to match actor names
6 actor_pattern = re.compile(r'([A-Z][a-z]+(?: [A-Z][a-z]+)+)')
7
8 # Find all matches
9 actors = actor_pattern.findall(input_string)
10
11 # Join the actors with a semicolon
12 result = '; '.join(actors)
13
14 return result
15
16# Example usage (from ChatGPT)
17input_text = "Aden Young and Marshall Napier starred in Shotgun Wedding"
18print(extract_actors(input_text))
19
20# Another test of the code that I added
21input_text = "Jane Tsentas and Cleo O'Hara starred in Evil Come Evil Go"
22print(extract_actors(input_text))
As usual, ChatGPT included an example that shows you how to invoke the function. I added another test. When you run extract_actors.py, you’ll find that ChatGPT’s test works fine, but the one I added doesn’t. And if you inspect the regular expression in the function extract_actors, you’ll see that it won’t work for names like “Cleo O’Hara,” which contain characters other than the letters a-z. This happened even though I included that name in my completion-prompt examples.
Tip
Even with good prompts, the solution produced with a GAI tool today won’t necessarily work in all the situations you care about. Problem solving involves iteration and thorough testing, even when you use GAI.
You can find lots of websites on the Internet that discuss prompt engineering. I consider most of their advice to be appropriate for getting better outputs from a human assistant as well as a GAI tool. Here are some basic rules of thumb:
When giving instructions, make them clear, detailed, and easy to follow.
If you want a comma-separated list, ask the tool to “return a comma-separated list.”
If you want the tool to say “I don’t know” when it doesn’t know the answer, tell it: “Say ‘I don’t know’ if you do not know the answer.”
Put your explicit instructions at the start or end of the prompt (i.e., not buried somewhere in it).
When a context for the model’s answer matters, state it.
If you want a high-quality and detailed answer, tell the tool to answer as if it was an expert.
If you want an answer appropriate for a middle-school student, say that.
When supplying examples, make them high-quality and diverse. If you cover the edge cases, it is more likely that the GAI tool will, too.
When the model seems to struggle with your task, try telling it to “think step by step.” No one knows why this seems to help, but it appears to nudge a GAI tool to decompose the main task into subtasks, and this decomposition seems to improve its reasoning.
Final thoughts. GAI is a tool for problem solving. Learn for yourself what it is good at doing and where its limitations are. Like computers, GAI tools are flexible. Read and think critically about what others have successfully done with GAI, and then experiment with it on problems that matter to you.
Your goal is to use it for tasks within the GAI tool’s frontier. Chosen appropriately, these GAI-assisted tasks will make you, like the consultants in the Harvard Business School study, more productive in producing high-quality outputs, especially in those areas where your skills could use a boost.
But be vigilantly skeptical. Always check and never blindly accept a GAI tool’s output.
When all is said and done, problem solving with GAI is still the same process that I described in Chapter 1. Whether you use Python or English to “program” the machine to solve your problem, your instructions need to be precise and carefully constructed.
Happy problem solving!